我知道这个问题比较老,但是我浏览了答案并且想到可能能够扩展一下问题中“动态”的部分,或者帮助别人解决问题。
首先,我建立了这个解决方案来解决几个同事在不稳定和大型数据集需要快速透视的问题。
这个解决方案需要创建一个存储过程,如果您的需求不能使用存储过程,请停止阅读。
此过程将获取透视语句的关键变量,以动态创建适用于不同表、列名和聚合的透视语句。静态列用作透视的 group by / 身份列(如果不需要可以从代码中删除,但在透视语句中非常常见,也是解决原始问题所必需的),透视列是生成最终结果列名称的地方,值列是应用聚合的列。Table 参数是包括模式(schema)在内的表名称(schema.tablename)。代码中的这一部分需要改进,因为它不够简洁。对于我来说,它能够正常工作,因为我的使用并不公开,而且 SQL 注入并不是一个问题。Aggregate 参数将接受任何标准 SQL 聚合函数,如 'AVG'、'SUM'、'MAX' 等。代码还默认使用 MAX 作为聚合函数,这不是必需的,但最初构建此函数的受众不理解透视,通常使用 max 作为聚合函数。
让我们从创建存储过程的代码开始。这个代码应该在 SSMS 2005 及以上版本中都可以工作,但我没有在 2005 或 2016 中进行测试,但我认为它也应该可以工作。
create PROCEDURE [dbo].[USP_DYNAMIC_PIVOT]
(
@STATIC_COLUMN VARCHAR(255),
@PIVOT_COLUMN VARCHAR(255),
@VALUE_COLUMN VARCHAR(255),
@TABLE VARCHAR(255),
@AGGREGATE VARCHAR(20) = null
)
AS
BEGIN
SET NOCOUNT ON;
declare @AVAIABLE_TO_PIVOT NVARCHAR(MAX),
@SQLSTRING NVARCHAR(MAX),
@PIVOT_SQL_STRING NVARCHAR(MAX),
@TEMPVARCOLUMNS NVARCHAR(MAX),
@TABLESQL NVARCHAR(MAX)
if isnull(@AGGREGATE,'') = ''
begin
SET @AGGREGATE = 'MAX'
end
SET @PIVOT_SQL_STRING = 'SELECT top 1 STUFF((SELECT distinct '', '' + CAST(''[''+CONVERT(VARCHAR,'+ @PIVOT_COLUMN+')+'']'' AS VARCHAR(50)) [text()]
FROM '+@TABLE+'
WHERE ISNULL('+@PIVOT_COLUMN+','''') <> ''''
FOR XML PATH(''''), TYPE)
.value(''.'',''NVARCHAR(MAX)''),1,2,'' '') as PIVOT_VALUES
from '+@TABLE+' ma
ORDER BY ' + @PIVOT_COLUMN + ''
declare @TAB AS TABLE(COL NVARCHAR(MAX) )
INSERT INTO @TAB EXEC SP_EXECUTESQL @PIVOT_SQL_STRING, @AVAIABLE_TO_PIVOT
SET @AVAIABLE_TO_PIVOT = (SELECT * FROM @TAB)
SET @TEMPVARCOLUMNS = (SELECT replace(@AVAIABLE_TO_PIVOT,',',' nvarchar(255) null,') + ' nvarchar(255) null')
SET @SQLSTRING = 'DECLARE @RETURN_TABLE TABLE ('+@STATIC_COLUMN+' NVARCHAR(255) NULL,'+@TEMPVARCOLUMNS+')
INSERT INTO @RETURN_TABLE('+@STATIC_COLUMN+','+@AVAIABLE_TO_PIVOT+')
select * from (
SELECT ' + @STATIC_COLUMN + ' , ' + @PIVOT_COLUMN + ', ' + @VALUE_COLUMN + ' FROM '+@TABLE+' ) a
PIVOT
(
'+@AGGREGATE+'('+@VALUE_COLUMN+')
FOR '+@PIVOT_COLUMN+' IN ('+@AVAIABLE_TO_PIVOT+')
) piv
SELECT * FROM @RETURN_TABLE'
EXEC SP_EXECUTESQL @SQLSTRING
END
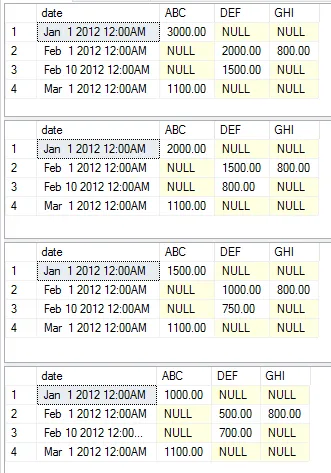
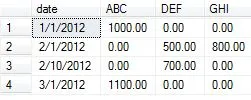
接下来,我们将为示例准备好数据。我从已接受答案中获取了数据示例,并添加了一些数据元素用于此概念验证,以展示聚合更改的不同输出。
create table temp
(
date datetime,
category varchar(3),
amount money
)
insert into temp values ('1/1/2012', 'ABC', 1000.00)
insert into temp values ('1/1/2012', 'ABC', 2000.00)
insert into temp values ('2/1/2012', 'DEF', 500.00)
insert into temp values ('2/1/2012', 'DEF', 1500.00)
insert into temp values ('2/1/2012', 'GHI', 800.00)
insert into temp values ('2/10/2012', 'DEF', 700.00)
insert into temp values ('2/10/2012', 'DEF', 800.00)
insert into temp values ('3/1/2012', 'ABC', 1100.00)
以下示例展示了不同的执行语句,以简单的示例来展示不同的聚合方式。我选择不更改静态、枢轴和值列,以保持示例的简单性。您可以直接复制并粘贴代码,开始自己尝试修改。
exec [dbo].[USP_DYNAMIC_PIVOT] 'date','category','amount','dbo.temp','sum'
exec [dbo].[USP_DYNAMIC_PIVOT] 'date','category','amount','dbo.temp','max'
exec [dbo].[USP_DYNAMIC_PIVOT] 'date','category','amount','dbo.temp','avg'
exec [dbo].[USP_DYNAMIC_PIVOT] 'date','category','amount','dbo.temp','min'
此操作分别返回以下数据集。
@cols进行排序,那么可以删除DISTINCT并在获取@cols列表时使用GROUP BY和ORDER BY。 - TarynGROUP BYc.category而不是DISTINCT更有效,因为它可以依赖于索引。在XQuery中,text()[1]比.更有效。另外,在更新的版本中,您可以使用STRING_AGG代替FOR XML`。 - Charlieface