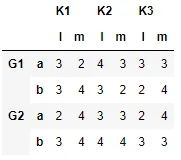
pandas 支持多层列名:
>>> x = pd.DataFrame({'instance':['first','first','first'],'foo':['a','b','c'],'bar':rand(3)})
>>> x = x.set_index(['instance','foo']).transpose()
>>> x.columns
MultiIndex
[(u'first', u'a'), (u'first', u'b'), (u'first', u'c')]
>>> x
instance first
foo a b c
bar 0.102885 0.937838 0.907467
由于它允许在列名称的第一级(在我的例子中是instance)区分实例,因此此功能非常有用,可以将同一数据帧的多个版本“水平”附加。
想象一下,我已经有了这样一个数据框:
a b c
bar 0.102885 0.937838 0.907467
是否有一种简便的方法来为列名添加另一个级别,类似于行索引的方法:
x['instance'] = 'first'
x.set_level('instance',append=True)