这是一个与现代处理器架构特性密切相关的复杂问题,你所认为的“随机读取比随机写入慢是因为CPU必须等待读取数据”并不经常被证实。我将详细说明几个原因。
1. 现代处理器非常有效地隐藏了读取延迟。
2. 内存写入比内存读取更加昂贵,尤其是在多核环境下。
3.
超标量可以同时执行多条指令,并改变指令执行顺序(
乱序执行)。这些功能的第一个原因是增加指令吞吐量,而其中最有趣的后果之一是处理器能够隐藏内存写入(或复杂操作、分支等)的延迟。
4. 为了解释这一点,让我们考虑一个简单的代码,将一个数组复制到另一个数组中。
for i in a:
c[i] = b[i]
一旦编译完成,由处理器执行的代码将会类似于这样
#1. (iteration 1) c[0] = b[0]
1a. read memory at b[0] and store result in register c0
1b. write register c0 at memory address c[0]
#2. (iteration 2) c[1] = b[1]
2a. read memory at b[1] and store result in register c1
2b. write register c1 at memory address c[1]
#1. (iteration 2) c[2] = b[2]
3a. read memory at b[2] and store result in register c2
3b. write register c2 at memory address c[2]
# etc
(这只是极度简化的,实际代码更加复杂,还需要处理循环管理、地址计算等问题,但这种简化模型目前已足够。)
正如问题中所说,对于读取操作,处理器必须等待实际数据。确实,1b 需要由 1a 获取的数据,并且只要 1a 没有完成,就无法执行。这种约束称为依赖关系,我们可以说 1b 依赖于 1a。依赖关系是现代处理器中的重要概念。依赖关系表达了算法(例如我将 b 写入 c)并且必须绝对遵守。但是,如果指令之间没有依赖关系,处理器将尝试执行其他挂起的指令,以保持其操作流水线始终处于活动状态。只要遵守依赖关系(类似于 as-if 规则),这可能导致乱序执行。
对于考虑的代码,在高级指令 2. 和 1.(或汇编指令 2a 和 2b 和前面的指令之间)之间没有依赖关系。实际上,即使在执行 1. 之前执行 2.,最终结果也将完全相同,处理器将尝试在完成 1a 和 1b 之前执行 2a 和 2b。2a 和 2b 之间仍然存在依赖关系,但两者都可以发出。类似地,对于 3a 和 3b,以及其他指令也是如此。这是一个强大的手段,用于隐藏内存延迟。如果由于某种原因 2、3 和 4 可以在 1 加载其数据之前终止,您甚至可能完全没有注意到任何减速。
这种指令级并行性由处理器中的一组“队列”管理。
保留站RS中有一个待处理指令队列(在最近的Pentium中为128个微指令)。一旦指令所需的资源可用(例如,指令1b的寄存器c1的值),该指令就可以执行。
在L1缓存之前,内存顺序缓冲区MOB中有一个待处理内存访问队列。这是为了处理内存别名并确保在同一地址处的内存写入或加载的顺序性(typ. 64个加载,32个存储)。
用于在寄存器中写回结果时强制顺序性的队列(重排序缓冲区或ROB,共168个条目),出于类似的原因。
还有其他一些队列,用于指令获取、μops生成、缓存中的写入和未命中缓冲区等。
在先前程序的某个执行点,RS中将有许多待处理的存储指令,MOB中将有几个加载指令,并且ROB中将有等待退役的指令。
一旦数据可用(例如读取终止),依赖的指令就可以执行,并且这会释放队列中的位置。但是如果没有终止发生,并且其中一个队列已满,则与该队列相关的功能单元将停顿(如果处理器缺少寄存器名称,也可能发生在指令发布时)。停顿会导致性能损失,并且为了避免这种情况,必须限制队列填充。
这篇文章解释了线性和随机内存访问之间的区别。
在线性访问中,1/由于更好的空间局部性和缓存可以预取具有规律模式的访问来进一步减少它,因此未命中的数量将更少,并且2/每当读操作结束时,它将涉及完整的缓存行,可以释放多个挂起的加载指令,从而限制指令队列的填充。这样处理器就会一直忙碌,内存延迟就会被隐藏起来。
对于随机访问,未命中的数量将更高,并且只有一个加载操作可以在数据到达时提供服务。因此,指令队列将迅速饱和,处理器停顿,内存延迟无法通过执行其他指令来隐藏。
处理器架构必须在吞吐量方面保持平衡,以避免队列饱和和停顿。实际上,在处理器的某个执行阶段通常会有数十条指令,全局吞吐量(即通过内存(或功能单元)为指令请求提供服务的能力)是确定性能的主要因素。这些挂起指令中的一些正在等待内存值的事实对性能影响较小...
...除非您具有长依赖链。
当指令必须等待先前指令完成时,就会存在依赖关系。使用读取结果是一种依赖性。当涉及到依赖链时,依赖关系可能成为问题。
例如,考虑代码for i in range(1,100000): s += a[i]。所有内存读取都是独立的,但是在s累加中存在依赖链。在上一个操作结束之前,不会发生任何加法操作。这些依赖关系将使预约站迅速填满,并在流水线中创建停顿。
但读取很少涉及依赖链。虽然仍有可能想象出所有读取都依赖于前一个的病态代码(例如
for i in range(1,100000): s = a[s]),但这在实际代码中很少见。问题来自于依赖链,而不是它是读取;如果是计算受限的依赖代码,情况会类似(甚至可能更糟),例如
for i in range(1,100000): x = 1.0/x+1.0。
因此,除了某些情况外,计算时间与读取依赖性关系不大,这要归功于超标量乱序执行隐藏延迟的事实。对于吞吐量,写入比读取更差。
原因#2:内存写入(特别是随机写入)比内存读取更昂贵
这与
caches的行为方式有关。高速缓存是由处理器存储部分内存(称为
line)的快速存储器。高速缓存行目前为64字节,并允许利用内存引用的空间局部性:一旦存储了一行,该行中的所有数据立即可用。这里的重要方面是
高速缓存和内存之间的所有传输都是行。
当处理器对数据执行读取时,高速缓存会检查数据所属的行是否在高速缓存中。如果没有,则从内存中提取该行,将其存储在高速缓存中,并将所需数据发送回处理器。
当处理器向内存写入数据时,缓存还会检查该行是否存在。如果该行不存在,则缓存无法将其数据发送到内存(因为所有传输都是基于行的),并执行以下步骤:
1. 缓存从内存中提取该行并将其写入缓存行。
2. 数据写入缓存并将整个行标记为已修改(脏)。
3. 当从缓存中抑制一行时,它会检查修改标志,如果该行已被修改,则将其写回内存(写回缓存)。
因此,每次内存写入都必须先进行内存读取以获取缓存中的行。这增加了额外的操作,但对于线性写入来说并不是很昂贵。第一个写入的字将会有一个缓存未命中和内存读取,但后续的写入只涉及缓存且命中。
但是,随机写入的情况非常不同。如果未命中的数量很重要,则每个缓存未命中都意味着在该行从缓存中弹出之前只有少量的写入,这显著增加了写入成本。如果一行在单次写入后被弹出,我们甚至可以认为写入的时间成本是读取的两倍。
需要注意的是,增加内存访问(读取或写入)的数量往往会饱和内存访问路径并全局减慢处理器与内存之间的所有传输。
在任何情况下,写入总是比读取更昂贵。而多核心增加了这个方面。
原因#3:随机写入在多核心中会导致缓存未命中。
我不确定这是否适用于问题的情况。虽然numpy BLAS例程是多线程的,但我认为基本数组复制不是。但它与此密切相关,并且是写入更昂贵的另一个原因。
多核的问题在于确保这样一种适当的
高速缓存一致性方式,即由几个处理器共享的数据在每个核的缓存中得到适当更新。这是通过诸如
MESI这样的协议完成的,该协议在写入缓存行之前更新缓存行,并使其他缓存副本无效(读取所有权)。
虽然在问题中(或其并行版本)实际上没有数据在核之间共享,但请注意,该协议适用于
缓存行。每当要修改缓存行时,它都会从持有最新副本的缓存中复制,本地更新并使所有其他副本无效,即使核正在访问缓存行的不同部分。这种情况称为
虚假共享,对于多核编程而言,这是一个重要问题。
关于随机写入的问题,缓存行是64字节,可以容纳8个int64,如果计算机有8个核心,则每个核心平均处理2个值。因此存在重要的虚假共享,这会减慢写入速度。
我们进行了一些性能评估。为了包括并行化影响的评估,它是用C执行的。我们比较了处理大小为N的int64数组的5个函数。
1.只是将b复制到c中(由编译器使用memcpy()实现)。
2.使用线性索引进行复制c[i] = b[d[i]],其中d[i]==i(read_linear)。
3.使用随机索引进行复制c[i] = b[a[i]],其中a是0..N-1的随机排列(read_random等同于原始问题中的fwd)。
4.使用线性写入c[d[i]] = b[i],其中d[i]==i(write_linear)。
5.使用随机写入c[a[i]] = b[i],其中a是0..N-1的随机排列(write_random等同于问题中的inv)。
代码已经使用gcc -O3 -funroll-loops -march=native -malign-double在Skylake处理器上编译。性能是用_rdtsc()测量的,并以每次迭代的周期数给出。函数被执行多次(1000-20000次,具体取决于数组大小),进行10个实验,并保留最小时间。
数组大小范围从4000到1200000。所有代码都经过了使用openmp的顺序版本和并行版本的测量。
以下是结果图表。函数用不同的颜色表示,顺序版本用粗线表示,而并行版本则用细线表示。
直接复制(显然)是最快的方法,由gcc使用高度优化的memcpy()实现。这是一种通过内存获取数据吞吐量估计的方法。对于小矩阵,每次迭代的循环周期(CPI)为0.8,而对于大矩阵,每次迭代的CPI为2.0。
线性读取性能大约比memcpy长两倍,但是有2个读取和1个写入,而直接复制只有1个读取和1个写入。此外,索引添加了一些依赖关系。最小值为1.56 CPI,最大值为3.8 CPI。线性写入略长(5-10%)。
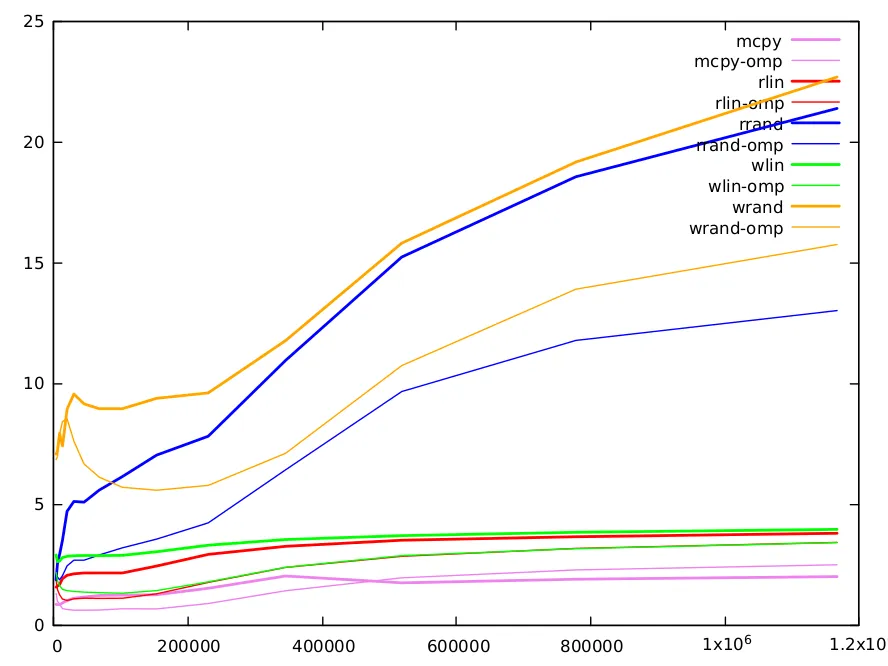
使用随机索引进行读写是原始问题的目的,并且值得更长的注释。以下是结果。
size 4000 6000 9000 13496 20240 30360 45536 68304 102456 153680 230520 345776 518664 777992 1166984
rd-rand 1.86821 2.52813 2.90533 3.50055 4.69627 5.10521 5.07396 5.57629 6.13607 7.02747 7.80836 10.9471 15.2258 18.5524 21.3811
wr-rand 7.07295 7.21101 7.92307 7.40394 8.92114 9.55323 9.14714 8.94196 8.94335 9.37448 9.60265 11.7665 15.8043 19.1617 22.6785
小数据(小于10k):L1缓存为32k,可以容纳一个4k的uint64数组。请注意,由于索引的随机性,在大约1/8的迭代后,L1缓存将完全填满随机索引数组的值(因为缓存行是64字节,可以容纳8个数组元素)。访问其他线性数组将会迅速生成许多L1缺失,并且我们必须使用L2缓存。L1缓存访问需要5个周期,但它是流水线式的,可以每个周期服务几个值。L2访问时间更长,需要12个周期。随机读取和写入的缺失量类似,但我们看到当数组大小很小时,我们完全支付了双倍的写入所需的访问。
中等数据(10k-100k):L2缓存为256k,可以容纳一个32k的int64数组。之后,我们需要进入L3缓存(12Mo)。随着大小的增加,L1和L2中的缺失次数增加,计算时间相应增加。两种算法具有类似数量的缺失,主要是由于随机读取或写入(其他访问是线性的,可以通过缓存非常有效地预取)。我们已经在B.M.答案中注意到了随机读取和写入之间的两倍因子。这可以部分地解释为写入的双重成本。
大数据(大于100k):方法之间的差异逐渐减小。对于这些大小,大量信息存储在L3缓存中。L3大小足以容纳一个完整的1.5M数组,并且行不太可能被驱逐。因此,对于写入,在初始读取之后,可以进行更多的写入而不会发生行驱逐,并且写入相对于读取的成本降低。对于这些大型大小,还有许多其他需要考虑的因素。例如,缓存只能服务有限数量的缺失(typ. 16),当缺失数量很大时,这可能是限制因素。
关于随机读写的并行omp版本,除了小尺寸数据,随机索引数组分布在多个缓存中可能没有优势,它们通常快两倍。对于大尺寸数据,由于虚假共享,随机读写之间的差距明显增加。
现有计算机架构的复杂性使得即使对于简单代码,定量预测几乎是不可能的,甚至行为的定性解释也很困难,必须考虑许多因素。正如其他答案中提到的,与python相关的软件方面也可能会产生影响。但是,虽然在某些情况下可能会发生,但大多数情况下,不能认为读取更昂贵,因为存在数据依赖性。
fwd实际上没有使用预先分配的c,而是创建(因此分配)了一个新的?稍后重复利用刚释放的c的副本,以便fwd可以超越inv?无论如何,希望整个事情不只是一个巨大的测量偏差 :-( - Paul Panzer