我有多个csv文件(每个文件包含N行(例如1000行)和43列)。
我想要从文件夹中读取几个csv文件到pandas中,并将它们合并成一个DataFrame。
但是,我还没有找出解决方法。
问题在于,DataFrame的最终输出(即frame = pd.concat(li, axis=0, ignore_index=True))将所有列(即43列)合并为一列(请参见附图)
代码截图
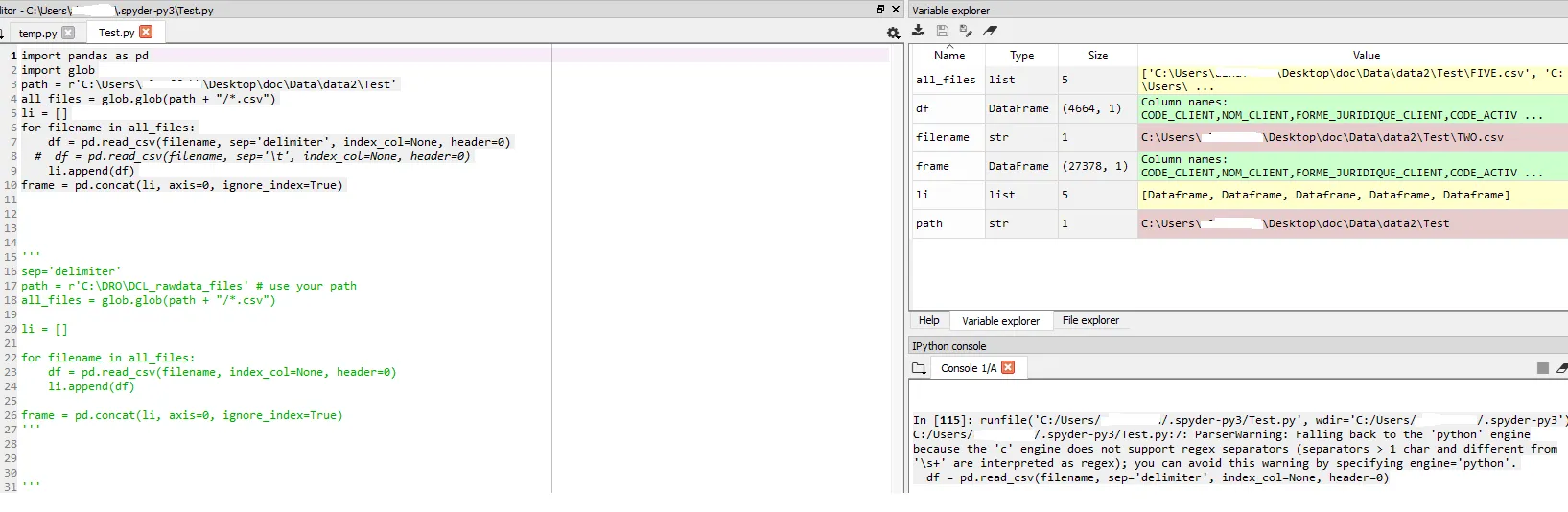{kind=link}
所选行和列的示例(文件一)
Client_ID Client_Name Pointer_of_Bins Date Weight
C0000001 POLYGONE TI006093 12/03/2019 0.5
C0000001 POLYGONE TI006093 12/03/2019 0.6
C0000001 POLYGONE TI006093 12/03/2019 1.4
C0000001 POLYGONE TI006897 14/03/2019 2.9
选定行和列的一个示例(第二个文件) 客户端ID 客户端名称 Bin指针 日期 重量 C0000001 POLYGONE TI006093 22/04/2019 1.5 C0000001 ALDI TI006098 22/04/2019 0.7 C0000001 ALDI TI006098 22/04/2019 2.4 C0000001 ALDI TI006898 24/04/2019 1.9
预期输出如下所示(合并多个可能包含成千上万行和数十列的文件,附带的数据只是一个示例,实际的CSV文件可能在每个文件中包含数千行和超过45列的行)
Client_ID Client_Name Pointer_of_Bins Date Weight
C0000001 POLYGONE TI006093 12/03/2019 0.5
C0000001 POLYGONE TI006093 12/03/2019 0.6
C0000001 POLYGONE TI006093 12/03/2019 1.4
C0000001 POLYGONE TI006897 14/03/2019 2.9
C0000001 POLYGONE TI006093 22/04/2019 1.5
C0000001 ALDI TI006098 22/04/2019 0.7
C0000001 ALDI TI006098 22/04/2019 2.4
C0000001 ALDI TI006898 24/04/2019 1.9
到目前为止,我已经完成了以下工作:
import pandas as pd
import glob
path = r'C:\Users\alnaffakh\Desktop\doc\Data\data2\Test'
all_files = glob.glob(path + "/*.csv")
li = []
for filename in all_files:
df = pd.read_csv(filename, sep='delimiter', index_col=None, header=0)
# df = pd.read_csv(filename, sep='\t', index_col=None, header=0)
li.append(df)
frame = pd.concat(li, axis=0, ignore_index=True)
sep='分隔符'。现在的代码会将所有数据框读取为一列。 - Quang Hoangsep ='delimiter'或使用文件中已使用的实际分隔符。这就是为什么我建议您分享一些虚拟数据(可能只有5列的4行),以便我们可以针对其进行测试。 - CypherX