我目前有一个类似于这个的数据框:
df <- tibble("Fam_Name" = c("Architecture", "Arts", "Business", "Managers", "Medicine", "Science"), "Code" = c(1,1,2, 2,3, 3), "Share_2002" = c(0.116, 3.442, 2.445, 1.932, 0.985, 0.321), "Share_2018" = c(0.161, 0.232, 1.234, 0.456, 0.089, 0.06))
我想创建一个名为
family的列表,其中包含三个其他列表:fam1,fam2,fam3
每个fam(i)列表都会包含两个数据框,分别称为fam_normal和fam_long,这些数据框是基于dplyr函数构建的,例如:fam_normal <- df %>% # I am not sure how to write this so that it is incorporated into the fam(i) list
filter(Code == i) %>%
rename("2002" = Share_2002,
"2018" = Share_2018)
fam_long <- fam_normal %>%
gather(Year, Share, 3:4) %>%
arrange(Fam_Name)
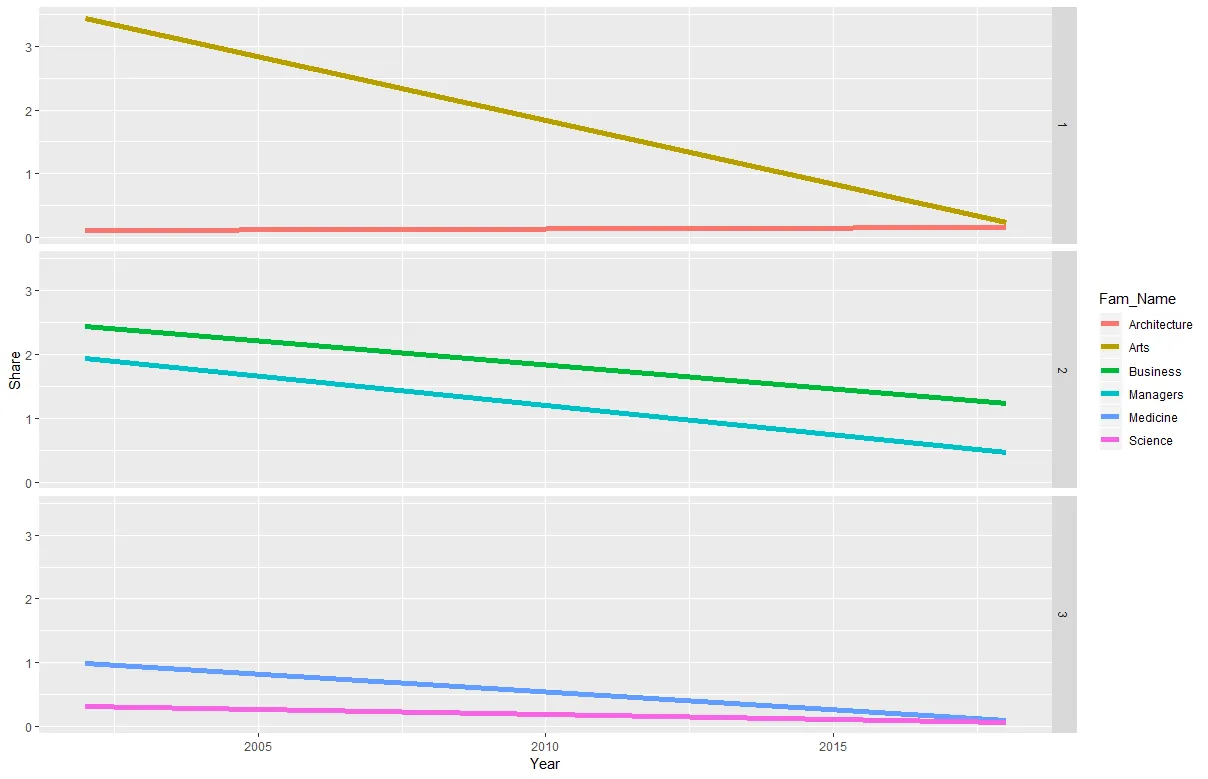
最终目标是为
fam列表中的每个fam(i)绘制一个图表,其中x轴为年份,y轴为股份。我的真实数据集有25个家族和更多年份。
rename_at(starts_with("Share_"), ~ gsub("Share_", "", .))批量重命名所有的Share_XXX为XXX。如果你有很多年份,这可能会很有用。 - asachet