我尝试跟随这个教程: https://blog.keras.io/building-powerful-image-classification-models-using-very-little-data.html
在基线模型中,它有
输出形状: 形状为(batch, filters, new_rows, new_cols)的4D张量
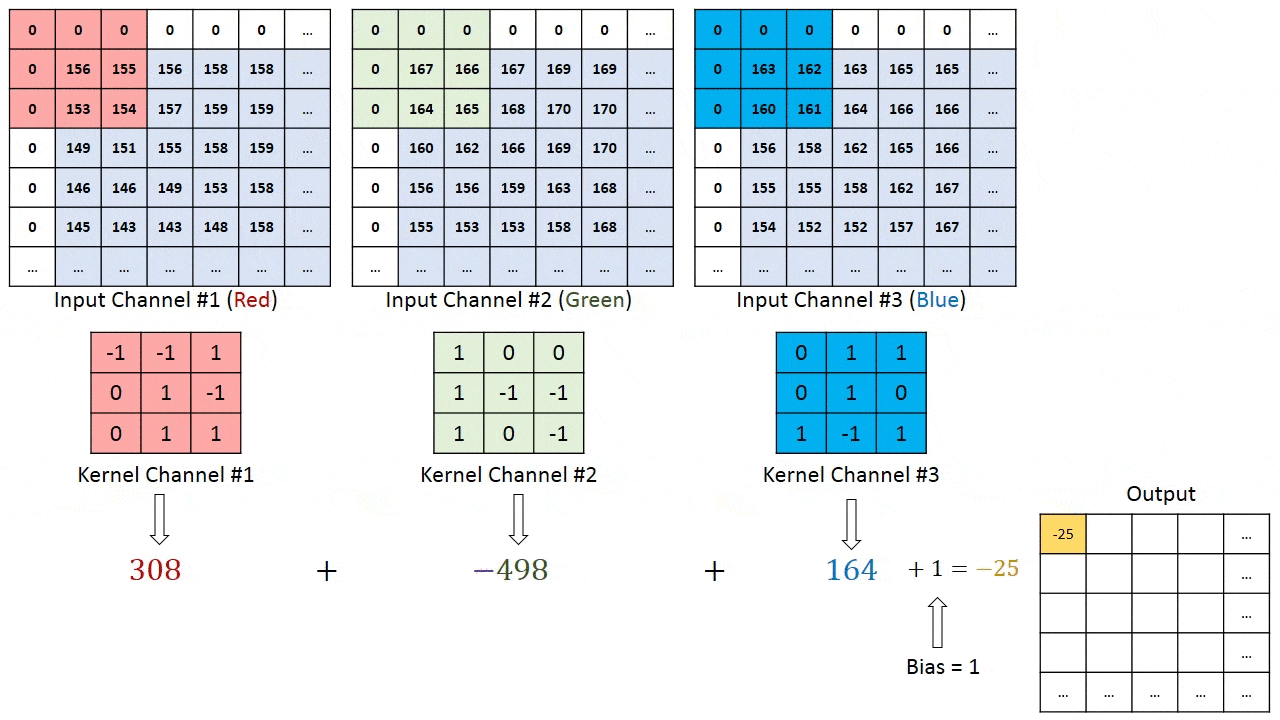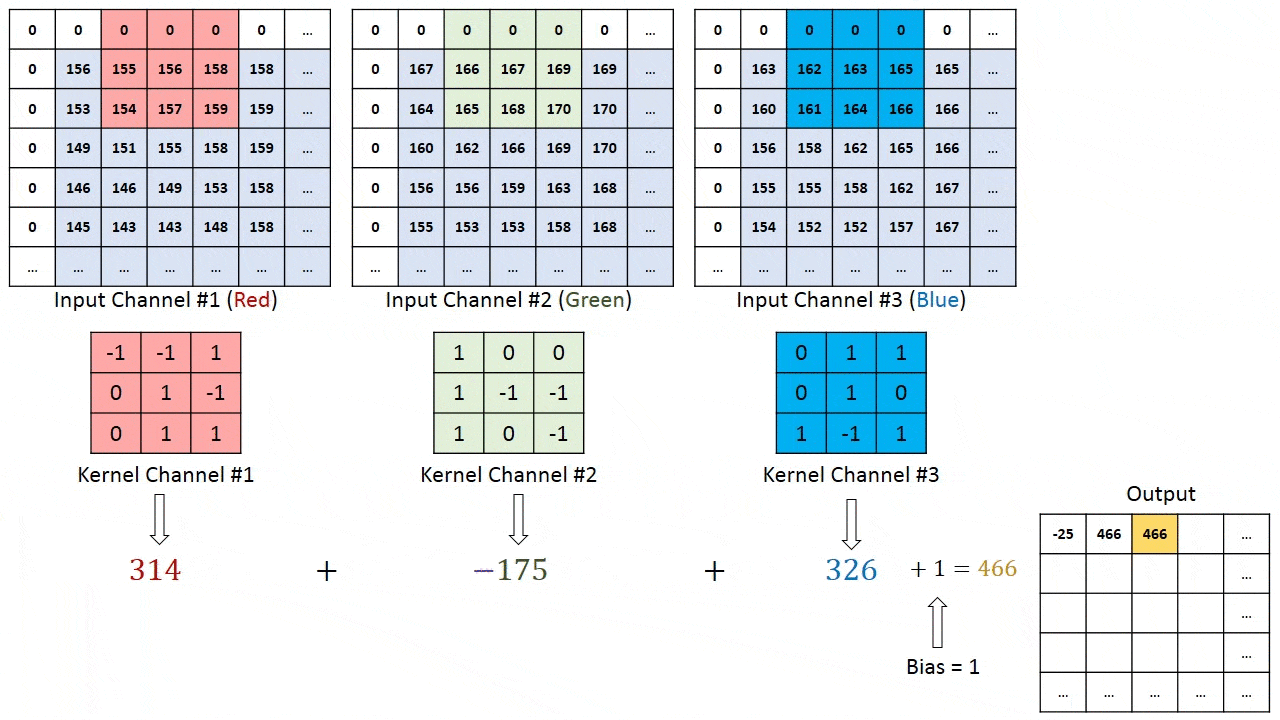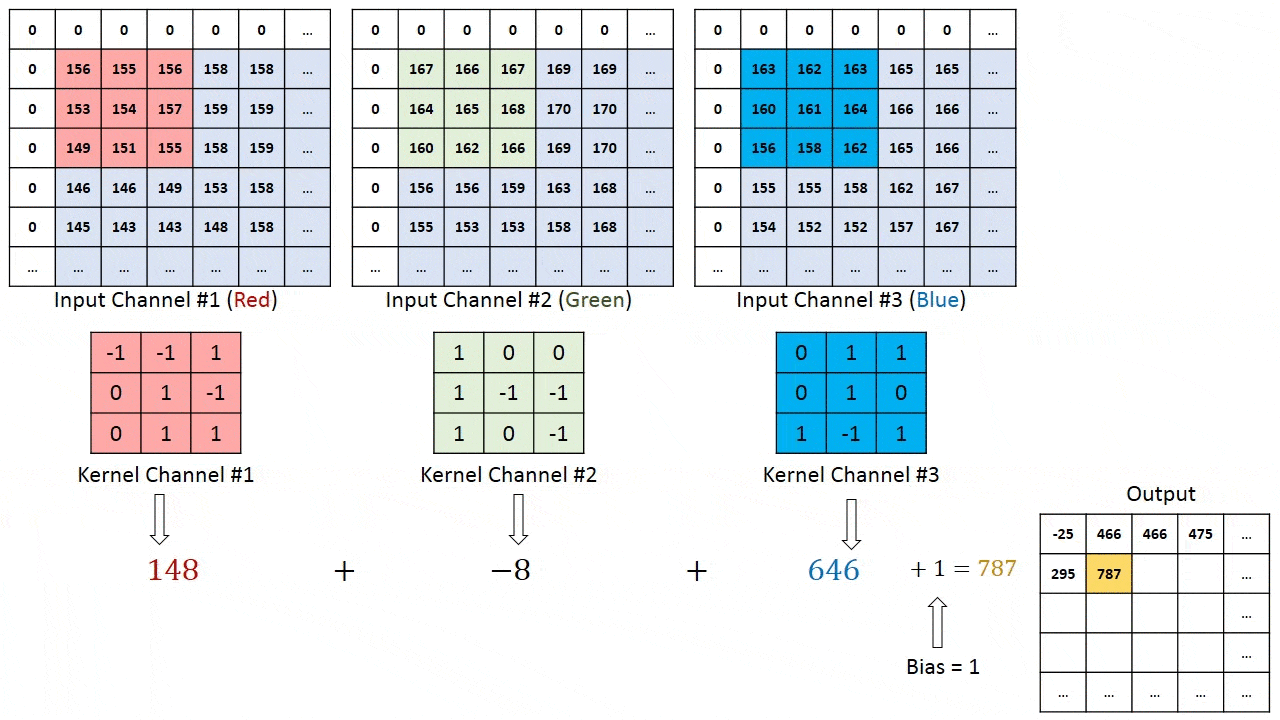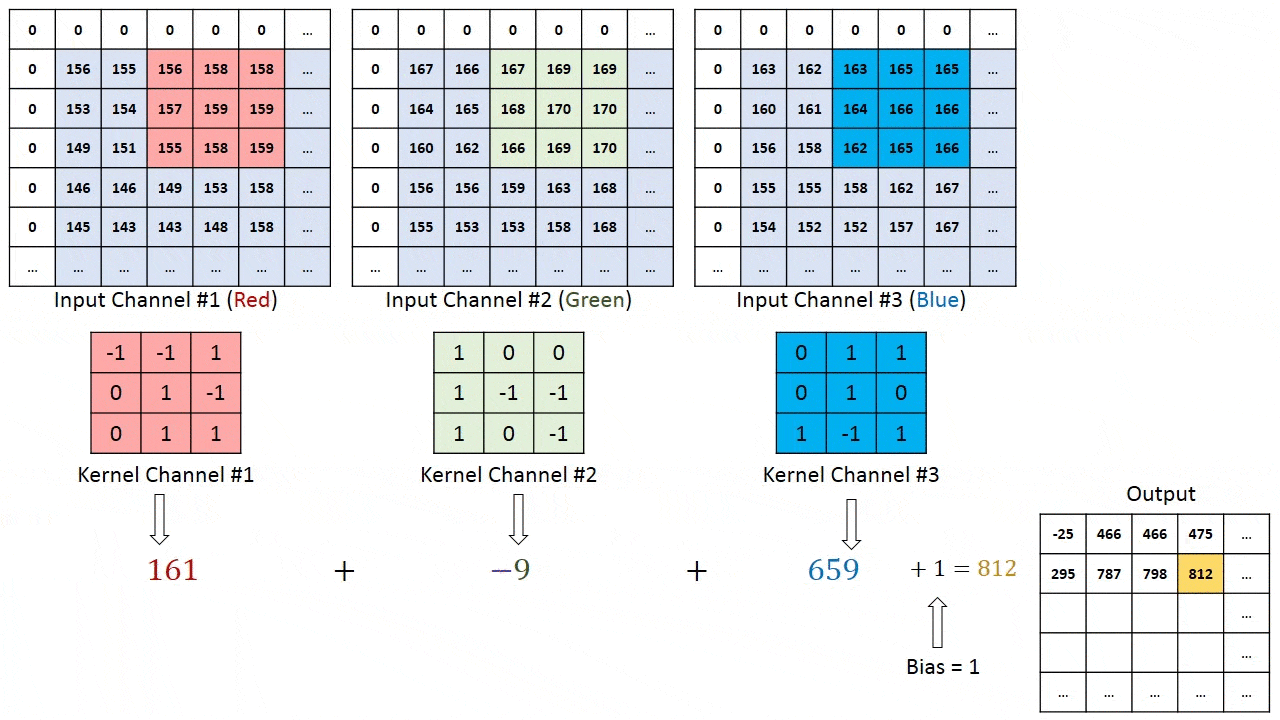
这似乎意味着输出形状将是32x148x148,我的问题是这种理解是否正确? 如果是这样,那么额外的过滤器来自哪里?
model.add(Conv2D(32, (3, 3), input_shape=(3, 150, 150)))
我对这里的输出形状不太明白。如果输入形状是3x150x150,卷积核大小为3x3,则输出形状不就是3x148x148了吗?(假设没有填充)。但是,根据Keras文档:输出形状: 形状为(batch, filters, new_rows, new_cols)的4D张量
这似乎意味着输出形状将是32x148x148,我的问题是这种理解是否正确? 如果是这样,那么额外的过滤器来自哪里?