使用这段代码,我在下面的图像中创建了一些字符周围的边界框:
import csv
import cv2
from pytesseract import pytesseract as pt
pt.run_tesseract('bb.png', 'output', lang=None, boxes=True, config="hocr")
# To read the coordinates
boxes = []
with open('output.box', 'rt') as f:
reader = csv.reader(f, delimiter=' ')
for row in reader:
if len(row) == 6:
boxes.append(row)
# Draw the bounding box
img = cv2.imread('bb.png')
h, w, _ = img.shape
for b in boxes:
img = cv2.rectangle(img, (int(b[1]), h-int(b[2])), (int(b[3]), h-int(b[4])), (0, 255, 0), 2)
cv2.imshow('output', img)
cv2.waitKey(0)
输出

我想要的是这个:

程序应该在边界框的X轴上绘制一条垂线(仅针对第一个和第三个文本区域。中间的不需要参与过程)。
目标是这样的(如果有另一种方法实现它,请解释):一旦我有了这两条线(或更好的是,坐标组),使用掩码来覆盖这两个区域。
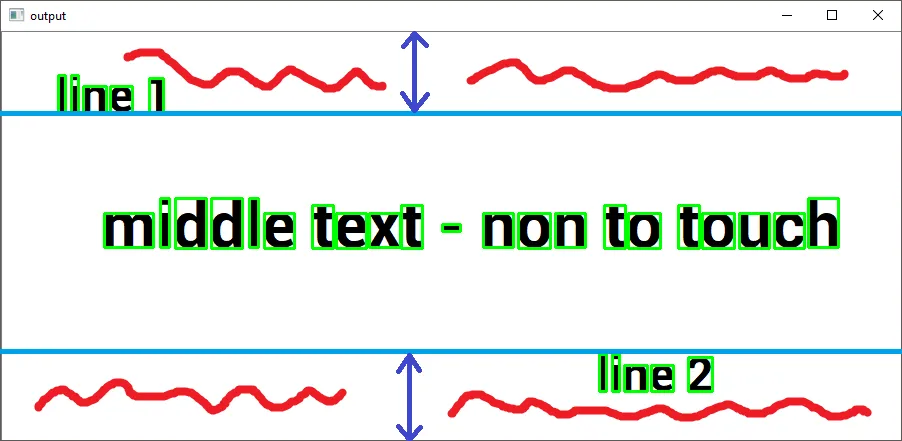
是否可能?
源图像:

按要求的CSV打印框:
[['l', '56', '328', '63', '365', '0'], ['i', '69', '328', '76', '365', '0'], ['n', '81', '328', '104', '354', '0'], ['e', '108', '328', '130', '354', '0'], ['1', '147', '328', '161', '362', '0'], ['m', '102', '193', '151', '227', '0'], ['i', '158', '193', '167', '242', '0'], ['d', '173', '192', '204', '242', '0'], ['d', '209', '192', '240', '242', '0'], ['l', '247', '193', '256', '242', '0'], ['e', '262', '192', '292', '227', '0'], ['t', '310', '192', '331', '235', '0'], ['e', '334', '192', '364', '227', '0'], ['x', '367', '193', '398', '227', '0'], ['t', '399', '192', '420', '235', '0'], ['-', '440', '209', '458', '216', '0'], ['n', '481', '193', '511', '227', '0'], ['o', '516', '192', '548', '227', '0'], ['n', '553', '193', '583', '227', '0'], ['t', '602', '192', '623', '235', '0'], ['o', '626', '192', '658', '227', '0'], ['t', '676', '192', '697', '235', '0'], ['o', '700', '192', '732', '227', '0'], ['u', '737', '192', '767', '227', '0'], ['c', '772', '192', '802', '227', '0'], ['h', '806', '193', '836', '242', '0'], ['l', '597', '49', '604', '86', '0'], ['i', '610', '49', '617', '86', '0'], ['n', '622', '49', '645', '75', '0'], ['e', '649', '49', '671', '75', '0'], ['2', '686', '49', '710', '83', '0']]
编辑:
要使用zindarod的答案,您需要安装tesserocr。通过pip install tesserocr安装可能会出现各种错误。
经过数小时的尝试安装和解决错误后,我找到了它的wheel版本(请参见下面答案中的我的评论...):在这里可以找到/下载它。
希望这可以帮助您...
