我正在Python 2.7.11中开发一个Agent类,它使用马尔可夫决策过程(MDP)来搜索GridWorld中最优策略π。我正在实现基本的值迭代算法,使用以下贝尔曼方程对所有GridWorld状态进行100次迭代:
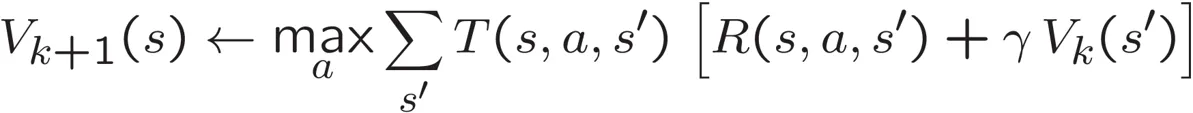
- T(s,a,s') 是成功从当前状态 s 通过执行动作 a 转移到后继状态 s' 的概率函数。
- R(s,a,s') 是从状态 s 转移到状态 s' 所获得的奖励。
- γ(伽马)是折扣因子,其中 0 ≤ γ ≤ 1。
- Vk(s') 是递归调用,一旦到达 s' 就重复计算。
- Vk+1(s) 代表经过足够的 k 次迭代后,Vk 迭代值将会收敛并等价于 Vk+1。
这个方程式来源于对 Q 值函数取最大值,这也是我在程序中使用的方法:
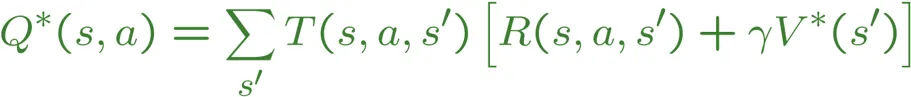
Agent时,需要传入一个MDP,它是一个抽象类,包含以下方法:# Returns all states in the GridWorld
def getStates()
# Returns all legal actions the agent can take given the current state
def getPossibleActions(state)
# Returns all possible successor states to transition to from the current state
# given an action, and the probability of reaching each with that action
def getTransitionStatesAndProbs(state, action)
# Returns the reward of going from the current state to the successor state
def getReward(state, action, nextState)
我的代理也传递了一个折扣因子和一定数量的迭代次数。我还使用一个字典来跟踪我的值。这是我的代码:
class IterationAgent:
def __init__(self, mdp, discount = 0.9, iterations = 100):
self.mdp = mdp
self.discount = discount
self.iterations = iterations
self.values = util.Counter() # A Counter is a dictionary with default 0
for transition in range(0, self.iterations, 1):
states = self.mdp.getStates()
valuesCopy = self.values.copy()
for state in states:
legalMoves = self.mdp.getPossibleActions(state)
convergedValue = 0
for move in legalMoves:
value = self.computeQValueFromValues(state, move)
if convergedValue <= value or convergedValue == 0:
convergedValue = value
valuesCopy.update({state: convergedValue})
self.values = valuesCopy
def computeQValueFromValues(self, state, action):
successors = self.mdp.getTransitionStatesAndProbs(state, action)
reward = self.mdp.getReward(state, action, successors)
qValue = 0
for successor, probability in successors:
# The Q value equation: Q*(a,s) = T(s,a,s')[R(s,a,s') + gamma(V*(s'))]
qValue += probability * (reward + (self.discount * self.values[successor]))
return qValue
这个实现是正确的,但我不确定为什么需要 valuesCopy 才能成功更新我的 self.values 字典。我尝试了以下方法来避免复制,但它无法工作,因为它返回的值略有不正确:
for i in range(0, self.iterations, 1):
states = self.mdp.getStates()
for state in states:
legalMoves = self.mdp.getPossibleActions(state)
convergedValue = 0
for move in legalMoves:
value = self.computeQValueFromValues(state, move)
if convergedValue <= value or convergedValue == 0:
convergedValue = value
self.values.update({state: convergedValue})
我的问题是,为什么在更新值时包含
self.values字典的副本是必要的,当valuesCopy = self.values.copy()每次迭代都会复制字典?更新原始值不应该导致相同的更新吗?
util.Counter()是什么? - styvaneCounter是一个继承自dictionary的类,将所有键的值默认为 0。在其定义中似乎没有任何update()方法。 - Jodo1992