我在数据库中有4个表,可以让我管理一种“检查清单”。对于每个病理学,我有一个大步骤(process)分成多个tasks。所有这些都与摘要表中的特定操作(progress.case_id)相关联。
database.pathology
+--------------+------------+
| id_pathology | name |
+--------------+------------+
| 1 | Pathology1 |
| 2 | Pathology2 |
| 3 | Pathology3 |
+--------------+------------+
database.process
+------------+----------+--------------+----------------+
| id_process | name | pathology_id | days_allocated |
+------------+----------+--------------+----------------+
| 1 | BigTask1 | 2 | 5 |
| 2 | BigTask2 | 2 | 3 |
| 3 | BigTask3 | 2 | 6 |
| ... | ... | ... | ... |
+------------+----------+--------------+----------------+
database.task
+---------+-------+------------+
| id_task | name | process_id |
+---------+-------+------------+
| 1 | Task1 | 1 |
| 2 | Task2 | 1 |
| 3 | Task3 | 1 |
| 4 | Task4 | 2 |
| ... | ... | ... |
+---------+-------+------------+
database.progress
+-------------+---------+---------+---------+------------+---------+
| id_progress | task_id | case_id | user_id | date | current |
+-------------+---------+---------+---------+------------+---------+
| 1 | 1 | 120 | 2 | 2015-11-02 | 1 |
| 2 | 2 | 120 | 2 | 2015-11-02 | 0 |
| 3 | 1 | 121 | 3 | 2015-11-02 | 1 |
+-------------+---------+---------+---------+------------+---------+
我需要展示类似这样的内容:
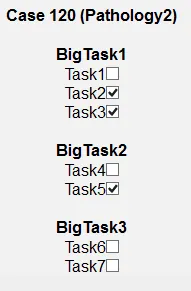
我的问题是:最高效的处理方式是什么?
查询只查询一个表(进度)以显示大多数内容,然后再查询其他表以获取不同流程和天数的名称是否更快?
也许联接函数更有效?
或者您认为我的数据库结构不太合适?
对于每种情况,我们可以有大约50个任务,并将当前字段转换为复选框。 还有一个后台脚本正在运行。 基于剩余天数分析提供的天数,以确定该特定案例是否可能会延迟。
对于每种情况,进度表已经填充了与案例的病理学相关的所有任务。 并且当前字段在开始时始终为“0”。
我已经尝试过多种方法,例如
$result = $db->prepare("SELECT DISTINCT process_id,process.name FROM task, progress,process WHERE progress.task_id = task.id_task AND task.process_id = process.id_process AND progress.case_id = ?");
$result->execute(array($id));
foreach($result as $row)
{
echo "<b>".$row[1]."</b><br>";
$result = $db->prepare("SELECT name,id_task FROM task WHERE process_id = ?");
$result->execute(array($row[0]));
foreach($result as $row)
{
echo $row[0];
$result = $db->prepare("SELECT user_id, date, current FROM progress WHERE progress.task_id = ? AND case_id = ?");
$result->execute(array($row[1], $id));
foreach($result as $row)
{
if($row[2] == 0)
{echo "<input type='checkbox' />";}
else
{
echo "<input type='checkbox' checked/>";
echo "user : ".$row[0]." date : ".$row[1]."<br>";
}
}
}
但我很确定我没有做对。我应该更改我的数据库基础设施吗?我应该使用特定的MySQL技巧吗?或者只是使用更有效率的PHP处理方式?
SET数据类型。 - Rick James