我在工作中的一个项目中需要计算三维空间点集的质心。目前,我采用一种看似简单但却很朴素的方法来计算 -- 即取每个点集的平均值,如下所示:
centroid = average(x), average(y), average(z)
其中x,y和z是浮点数数组。 我似乎记得有一种方法可以获得更精确的质心,但我没有找到一个简单的算法来实现这一点。 有人有任何想法或建议吗? 我正在使用Python进行此操作,但我可以从其他语言的示例进行调整。
我在工作中的一个项目中需要计算三维空间点集的质心。目前,我采用一种看似简单但却很朴素的方法来计算 -- 即取每个点集的平均值,如下所示:
centroid = average(x), average(y), average(z)
其中x,y和z是浮点数数组。 我似乎记得有一种方法可以获得更精确的质心,但我没有找到一个简单的算法来实现这一点。 有人有任何想法或建议吗? 我正在使用Python进行此操作,但我可以从其他语言的示例进行调整。
与通常的说法相反,定义(和计算)点云中心点的方法是不同的。第一种也是最常见的解决方法已经由你提出,我不会争辩这有任何问题:
centroid = average(x), average(y), average(z)
“问题”在于它会根据点的分布“扭曲”你的中心点。例如,如果你假设所有的点都在一个立方体或其他几何形状内,但大部分点都放在上半部分,你的中心点也将朝那个方向移动。
作为替代,你可以使用每个维度的数学中间值(极值的平均值)来避免这种情况:
middle = middle(x), middle(y), middle(z)
当你不太关心点的数量,更关心全局边界框时,可以使用此方法,因为它只是围绕你的点的边界框的中心。
最后,你也可以在每个维度上使用median(中间元素):
median = median(x), median(y), median(z)
现在,这将有点相反于middle,实际上可以帮助你忽略点云中的异常值并根据你的点的分布找到中心点。
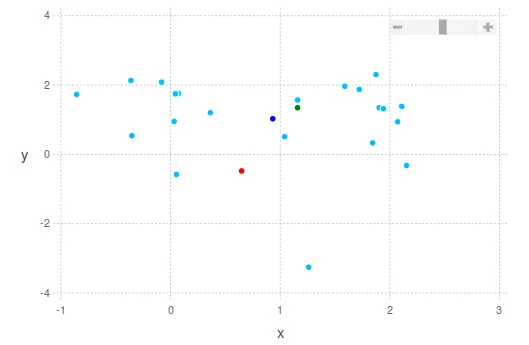
寻找“好”的中心点更加稳健的方式也许是忽略每个维度的最高和最低10%,然后计算average或median。如你所见,可以用不同的方法定义中心点。下面我将展示两个2D点云的例子,考虑这些建议。
深蓝色点是平均质心。 绿色显示中位数。 红色显示中间值。
在第二张图片中,您将看到我之前所说的情况:绿点“更靠近”点云的最密集部分,而红点则距离它更远,考虑到点云的最极端边界。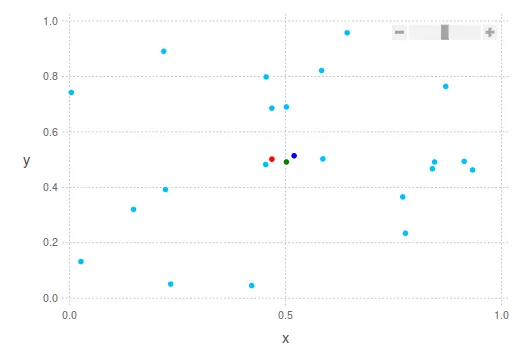
不,这是点集的质心唯一的公式。请参阅维基百科:http://en.wikipedia.org/wiki/Centroid
N # number of points
sums = dict(x=0,y=0,z=0) # sums of the locations for each point
每当创建或删除点时,就会更改N和sums。这将使计算的时间复杂度从O(N)变为O(1),但代价是每次创建、移动或删除点时需要进行更多的工作。
import numpy as np
vectors = np.array(Listv)
centroid = np.mean(vectors, axis=0)
“更准确的质心”我认为质心是按照您计算的方式定义的,因此不存在“更准确的质心”。
是的,那就是正确的公式。
如果你有大量的点,你可以利用问题的对称性(无论是圆柱形、球形还是镜像)。否则,你可以借鉴统计学的方法,对随机选取的一些点进行平均,这样就会有一些误差。
没错,你正在计算质心或平均向量。