关于Pandas:
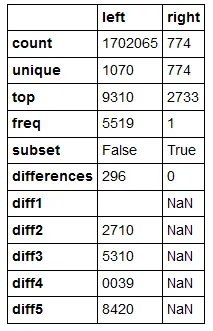
df.merge() 方法,有没有一种方便的方法来获取合并的摘要统计信息(比如匹配数量、未匹配数量等等)。我知道这些统计数据取决于how='inner'标志,但是知道在使用内联结时被“丢弃”了多少内容会很方便。我可以简单地使用以下代码:df = df_left.merge(df_right, on='common_column', how='inner')
set1 = set(df_left[common_column].unique())
set2 = set(df_right[common_column].unique())
set1.issubset(set2) #True No Further Analysis Required
set2.issubset(set1) #False
num_shared = len(set2.intersection(set1))
num_diff = len(set2.difference(set1))
# And So on ...
但是我认为这可能已经被实施了。我错过了吗(例如,像合并操作中的report=True,会返回一个new_dataframe和一个报告序列或数据帧)
set(df_right[common_column].unique())和set(df_right[common_column])是一样的 :) - Andy Hayden