我该如何将两个拥有不同列名的pandas DataFrame按照两列合并,并保留其中一列?
df1 = pd.DataFrame({'UserName': [1,2,3], 'Col1':['a','b','c']})
df2 = pd.DataFrame({'UserID': [1,2,3], 'Col2':['d','e','f']})
pd.merge(df1, df2, left_on='UserName', right_on='UserID')
这提供了一个像这样的DataFrame:
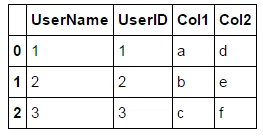
但显然我是在UserName和UserID上合并,所以它们是相同的。我希望它看起来像这样。有没有简洁的方法可以做到这一点?
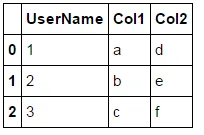
我能想到的方法只有将合并前的列重命名为相同的名称,或者在合并后删除其中一个。如果pandas自动删除其中一个或者我可以执行类似于以下代码的操作将会很好:
pd.merge(df1, df2, left_on='UserName', right_on='UserID', keep_column='left')