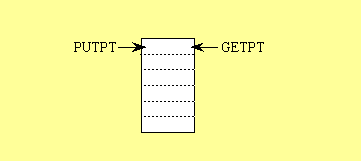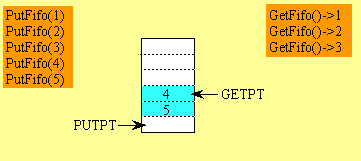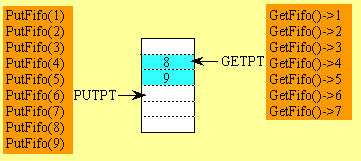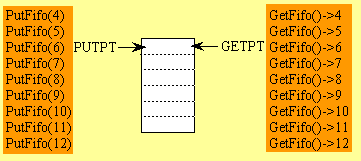
更新:以下是来自vartec回答中的循环缓冲区技术实现(建立在我的原始答案基础上,对于那些好奇的人,下面仍然保留):
from cStringIO import StringIO
class FifoFileBuffer(object):
def __init__(self):
self.buf = StringIO()
self.available = 0
self.size = 0
self.write_fp = 0
def read(self, size = None):
"""Reads size bytes from buffer"""
if size is None or size > self.available:
size = self.available
size = max(size, 0)
result = self.buf.read(size)
self.available -= size
if len(result) < size:
self.buf.seek(0)
result += self.buf.read(size - len(result))
return result
def write(self, data):
"""Appends data to buffer"""
if self.size < self.available + len(data):
new_buf = StringIO()
new_buf.write(self.read())
self.write_fp = self.available = new_buf.tell()
read_fp = 0
while self.size <= self.available + len(data):
self.size = max(self.size, 1024) * 2
new_buf.write('0' * (self.size - self.write_fp))
self.buf = new_buf
else:
read_fp = self.buf.tell()
self.buf.seek(self.write_fp)
written = self.size - self.write_fp
self.buf.write(data[:written])
self.write_fp += len(data)
self.available += len(data)
if written < len(data):
self.write_fp -= self.size
self.buf.seek(0)
self.buf.write(data[written:])
self.buf.seek(read_fp)
原始答案(已被上面的答案取代):
你可以使用缓冲区并跟踪起始索引(读取文件指针),在它变得太大时偶尔压缩它(这应该会产生相当好的平均性能)。
例如,可以像这样包装StringIO对象:
from cStringIO import StringIO
class FifoBuffer(object):
def __init__(self):
self.buf = StringIO()
def read(self, *args, **kwargs):
"""Reads data from buffer"""
self.buf.read(*args, **kwargs)
def write(self, *args, **kwargs):
"""Appends data to buffer"""
current_read_fp = self.buf.tell()
if current_read_fp > 10 * 1024 * 1024:
new_buf = StringIO()
new_buf.write(self.buf.read())
self.buf = new_buf
current_read_fp = 0
self.buf.seek(0, 2)
self.buf.write(*args, **kwargs)
self.buf.seek(current_read_fp)