我正在编程激光雕刻图像的半色调处理。在给定的设置下,激光只能打开或关闭,因此我可以给它具有1位深度的二进制图像。因此,我将具有8位深度(0到255)的灰度图像转换为具有1位深度(0到1)的二进制图像。
我在下面包含了两个示例图像。左边是灰度图像。右边是用3x3的二进制像素替换每个像素的结果。结果看起来相似,因为灰色来自黑色像素的密度。
结果为:
我查看了如何加速Python嵌套循环?和在图像中循环像素,但我没有立即看到如何矢量化此操作。
如何加速这个查找操作的嵌套循环?
我在下面包含了两个示例图像。左边是灰度图像。右边是用3x3的二进制像素替换每个像素的结果。结果看起来相似,因为灰色来自黑色像素的密度。


我的当前尝试使用嵌套循环来访问像素,并在输出图像中用字典中查找的值替换像素:
import math
import time
import numpy as np
TONES = [[0, 0,
0, 0],
[0, 1,
0, 0],
[1, 1,
0, 0],
[1, 1,
0, 1],
[1, 1,
1, 1]]
def process_tones():
"""Converts the tones above to the right shape."""
tones_dict = dict()
for t in TONES:
brightness = sum(t)
bitmap_tone = np.reshape(t, (2, 2)) * 255
tones_dict[brightness] = bitmap_tone
return(tones_dict)
def halftone(gray, tones_dict):
"""Generate a new image where each pixel is replaced by one with the values in tones_dict.
"""
num_rows = gray.shape[0]
num_cols = gray.shape[1]
num_tones = len(tones_dict)
tone_width = int(math.sqrt(num_tones - 1))
output = np.zeros((num_rows * tone_width, num_cols * tone_width),
dtype = np.uint8)
# Go through each pixel
for i in range(num_rows):
i_output = range(i * tone_width, (i + 1)* tone_width)
for j in range(num_cols):
j_output = range(j * tone_width, (j + 1)* tone_width)
pixel = gray[i, j]
brightness = int(round((num_tones - 1) * pixel / 255))
output[np.ix_(i_output, j_output)] = tones_dict[brightness]
return output
def generate_gray_image(width = 100, height = 100):
"""Generates a random grayscale image.
"""
return (np.random.rand(width, height) * 256).astype(np.uint8)
gray = generate_gray_image()
tones_dict = process_tones()
start = time.time()
for i in range(10):
binary = halftone(gray, tones_dict = tones_dict)
duration = time.time() - start
print("Average loop time: " + str(duration))
结果为:
平均循环时间:3.228989839553833对于一个100x100的图像,平均循环需要3秒,与OpenCV的函数相比似乎有些长。
我查看了如何加速Python嵌套循环?和在图像中循环像素,但我没有立即看到如何矢量化此操作。
如何加速这个查找操作的嵌套循环?
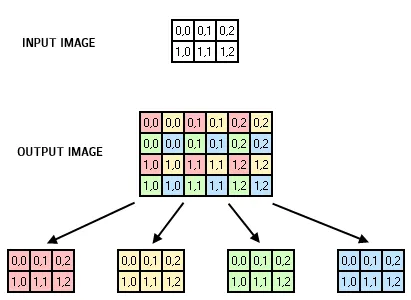
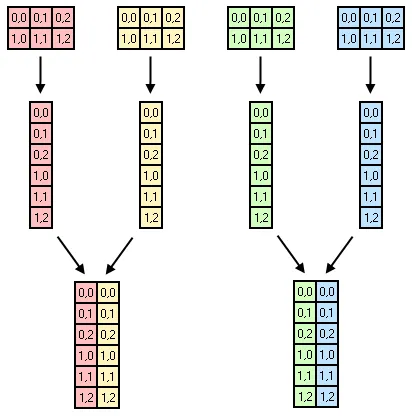
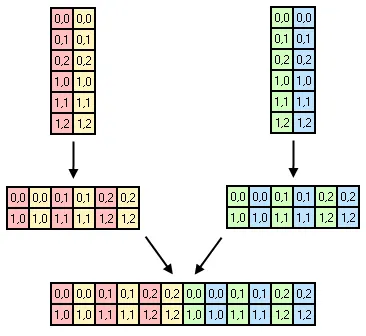
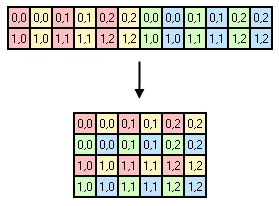


print语句的if块。 - C.Nivs