数据集的可重复代码:
df = {'player' : ['a','a','a','a','a','a','a','a','a','b','b','b','b','b','b','b','b','b','c','c','c','c','c','c','c','c','c'],
'week' : ['1','1','1','2','2','2','3','3','3','1','1','1','2','2','2','3','3','3','1','1','1','2','2','2','3','3','3'],
'category': ['RES','VIT','MATCH','RES','VIT','MATCH','RES','VIT','MATCH','RES','VIT','MATCH','RES','VIT','MATCH','RES','VIT','MATCH','RES','VIT','MATCH','RES','VIT','MATCH','RES','VIT','MATCH'],
'energy' : [75,54,87,65,24,82,65,42,35,25,45,87,98,54,82,75,54,87,65,24,82,65,42,35,25,45,98] }
df = pd.DataFrame(data= df)
df = df[['player', 'week', 'category','energy']]
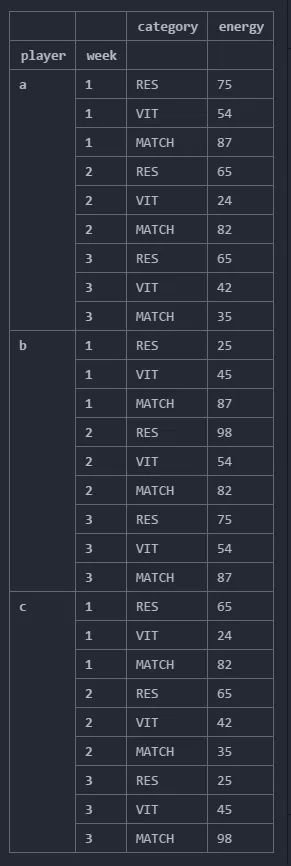
我需要找到“对于每个球员,找到他的能量最大的那一周,并显示所有类别、该周的能量值”。
所以我做了以下操作:
1.将球员和周设置为索引
2.遍历索引以找到能量的最大值并返回其值
df = df.set_index(['player', 'week'])
for index, row in df1.iterrows():
group = df1.ix[df1['energy'].idxmax()]
输出结果:
category energy
player week
b 2 RES 98
2 VIT 54
2 MATCH 82
这个输出结果是针对整个数据集中最大的能量值,我希望得到每个玩家在该周内所有其他类别下的最大能量值。
预期输出:
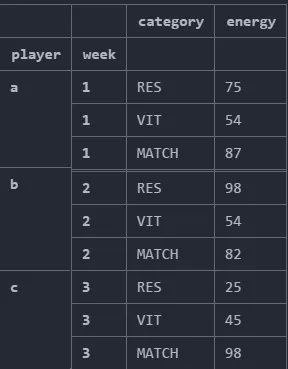
我尝试了评论区提到的groupby方法,
df.groupby(['player','week'])['energy'].max().groupby(level=['player','week'])
获得的输出为:
energy category
player week
a 1 87 VIT
2 82 VIT
3 65 VIT
b 1 87 VIT
2 98 VIT
3 87 VIT
c 1 82 VIT
2 65 VIT
3 98 VIT
df.groupby(by=['player','week'])['energy','category'].max(),但它没有给我预期的输出。 - vishnu prashanth