我正在尝试优化运行长度编码。我考虑使用SIMD实现它。我花了几个小时研究算法,但进展不大。是否值得一试?我正在使用Neon。
谢谢。
我正在尝试优化运行长度编码。我考虑使用SIMD实现它。我花了几个小时研究算法,但进展不大。是否值得一试?我正在使用Neon。
谢谢。
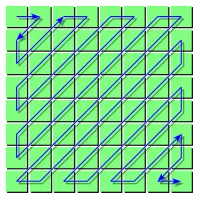
ZigZag通常与RLE运行结合使用,因此我们具有非线性内存访问的RLE,并且应优化两个函数。
警告!JPEG中的RLE仅用于零元素!请检查ISO/IEC 10918-1:1993标准的F.1.2.2.1、F.1.2.2.3和图F.2。
一些实现:
有libjpeg-turbo(主页是libjpeg-turbo.org),它的一些分支在2010-2011年被Linaro为ARM进行了优化。
这个分支中有优化列表:
- 10 - ARM NEON量化代码的优化,用浮点数乘法替代整数除法。这个优化函数现在比原始的C变体快了近3倍 - jcdctmgr.c - Siarhei Siamashka 2010-11-10
- 9 - ARM汇编优化'encode_one_block'(ARM汇编优化'encode_one_block'。比原始的C变体快了近2倍。) - jchuff.c - Siarhei Siamashka 2010-11-10
- 8 - ARM NEON优化版本的'rgb_ycc_convert' - Siarhei Siamashka 2010-11-10
- 7 - ARM NEON优化版本的'ycc_rgb_convert' - Siarhei Siamashka 2010-11-10
- 6 - 对'convsamp'进行了小的ARM NEON优化 - Siarhei Siamashka 2010-11-10
- 5 - ARM NEON优化版本的'jpeg_fdct_ifast' - Siarhei Siamashka 2010-11-10
- 4 - ARM NEON优化版本的'jpeg_idct_ifast' - Siarhei Siamashka 2010-11-10
- 3 - ARM NEON优化版本的'jpeg_idct_4x4' - Siarhei Siamashka 2010-11-10
修订版9是对jchuff.c文件进行的ARM优化,针对函数encode_one_block,它可以同时编码块的AC和DC分量;但是它是在不使用NEON的情况下完成的。
/* Encode a single block's worth of coefficients */
LOCAL(boolean) encode_one_block
find_last_nonzero_index辅助函数中。(它是使用ruby generator生成的)或者在linaro git中。它被安排用于双发射Cortex-A8:* Find last nonzero coefficient and produce output in natural order,
* instructions are scheduled to make use of ARM Cortex-A8 dual-issue
* capability
这是该函数的相应C代码:
LOCAL(int)
find_last_nonzero_index (JCOEFPTR block, JCOEFPTR out)
{
int tmp, i, n = 0;
for (i = 1; i < DCTSIZE2; i++) {
if ((tmp = block[jpeg_natural_order[i]]) != 0)
n = i;
out[i] = tmp;
}
return n;
这里有关于RLE本身的ARM或NEON优化,但我认为这个汇编代码可以帮助RLE,将其转换为线性内存访问版本(encode_one_block,在ifdef __arm__下):
for (k = 2; k <= last_nonzero_index; k += 2) {
innerloop(k);
}
innerloop宏中使用的r是RLE计数器。
这个带有手动编码ZigZag(适用于Cortex-A8)的线性RLE版本应该比原始的C版本更快,即使对于Cortex-A9也是如此。感谢Siarhei Siamashka!
PS:当前版本的libjpeg-turbo在这个RLE中没有arm优化: encode_one_block, jchuff.c的第454行,rev929 - innerloop被轻微重写为kloop,但RLE仍然以非线性方式完成;Zigzag与其未分开。
关于NEON的一些想法
NEON具有32个寄存器集,每个寄存器64位宽(D0..D31;根据Anderson @ ELC 2011,第5页),理论上可以用于存储64个16位系数并实现ZigZag+RLE。仍在寻找实现方法...
在MPEG标准中也有类似的zig-zag + RLE算法,而且还有一些针对x86和arm的SIMD实现。这里有一篇关于x264dev的博客文章blog post in x264dev;使用SSSE3为x86实现了8x8 zigzag x264_zigzag_scan_8x8_frame。但是对于ARM,x264只有4x4 NEON zigzag。
PS: 对于我和任何不了解Jpeg内部结构的人来说,Cardiff CM0340讲座幻灯片中有简短易懂的介绍JPEG编码。
PPS (更新于2013年2月18日13:30):为了优化RLE编码,我们可以进行预扫描,在AC系数中间搜索零,然后使用这些预计算的数据。我们甚至可以将其保存为半字节或位于某些NEON寄存器中的位。
2月18日更新:补丁作者称提交9的注释不准确。与jpeg6b相比,此代码的性能提高了2倍,而不是libjpeg-turbo。他说,像libjpeg-tubro一样展开63次(在某些测试中略微优于其他方案)的速度几乎与此汇编语言解决方案相同。