我该如何在目录/子目录中搜索PDF文件的内容?我正在寻找一些命令行工具。似乎grep无法搜索PDF文件。
如何搜索多个PDF文件的内容?
290
- Jestin Joy
4
6由于PDF是一种二进制格式,其中的文本通常被压缩或以多种方式进行编码,因此Grep无法工作。 - mark stephens
4这是一个图形用户界面解决方案:Adobe Reader,请参见 https://wikispaces.psu.edu/display/training/Search+for+Text+in+Multiple+PDFs+with+Adobe+Reader。 - Martin Thoma
3好的,我会尽力进行翻译。以下是需要翻译的内容:相关链接:http://unix.stackexchange.com/questions/6704/grep-pdf-files - Flow
4Adobe Reader可以正常使用,但它不支持索引功能;因此,如果你有很多文件,它的速度会很慢。是否有任何索引解决方案? - Irina Rapoport
15个回答
1
有一个开源共享资源的grep工具crgrep,它可以在PDF文件以及其他资源中搜索,例如嵌套在档案中的内容、数据库表、图像元数据、POM文件依赖和Web资源,以及这些的组合,包括递归搜索。
文件选项卡下的完整描述几乎涵盖了该工具支持的内容。
我作为一个开源工具开发了crgrep。
- Craig
2
Craig - 你和那个项目有联系吗?如果有的话,在你的回答中应该声明。我这么说是因为你刚刚在两个其他旧问题上发布了几乎相同的答案... - Stephen C
更新帖子以澄清我是 crgrep 的作者。 - Craig
0
你需要一些工具,如pdf2text,先将你的pdf转换为文本文件,然后在文本中搜索。(你可能会错过一些信息或符号)。
如果你正在使用编程语言,那么可能有专门用于此目的的pdf库。例如,Perl的http://search.cpan.org/dist/CAM-PDF/。
- Nylon Smile
0
尝试在类似上面的简单脚本中使用“acroread”。
- acathur
0
感谢这里提出的所有好主意!
我尝试了xargs方法,但正如在这里指出的那样,xargs会使包括打印实际文件名变得不可能(或非常困难)...
所以我尝试了用GNU parallel完成整个事情。
parallel "pdftotext -q {} - | grep --with-filename --label='['{}']' --color=always --context=5 'pattern'" ::: *.pdf
- 这将打印出不仅是模式,而且还有上下文中的5行(使用
--context=5)。 - 使用
-q,pdftotext将不会打印任何错误消息或警告(安静模式)。 - 我使用方括号
[]作为标签,而不是花括号{}。如果您想要花括号,则--label='{'{}'}'可以实现。请注意,{}将被GNU parallel替换为实际文件名,例如'Example portable document file name with spaces.pdf'({}已经使用单引号')。 - 通过使用
--label={},只会打印文件名,这可能是显示文件名的首选方式。 - 我还注意到,当我尝试时,输出没有颜色,除非通过添加
--color=always与grep强制执行。 - 对于不区分大小写的关键字搜索,可以在grep命令中添加
--ignore-case。
如果应递归处理所有PDF文件,包括当前目录(.)中的所有子目录,则可以通过find来完成:
find . -type f -iname '*.pdf' -print0 | parallel -0 "pdftotext -q {} - | grep --with-filename --label='['{}']' --color=always --context=5 'pattern'"
- 使用 find 命令时,
-iname '*.pdf'不区分大小写,而-name '*.pdf'只包括小写 .pdf 文件(通常情况)。由于有时我也会遇到扩展名为大写 .PDF 的 Windows PDF 文件,所以我更倾向于使用-iname。 - 上述命令也适用于
-printfind 选项(而非-print0),因此它将基于行(每行一个文件名),然后并行命令中必须省略-0(NUL 分隔符)。 - 同样,在 grep 命令中包括
--ignore-case将使搜索忽略大小写。
在整个命令行中玩耍时的一般建议是,使用 parallel --dry-run 将打印将要执行的命令。
$ find . -type f -iname '*.pdf' -print0 | parallel --dry-run -0 "pdftotext -q {} - | grep --with-filename --label='['{}']' --color=always --ignore-case --context=5 'pattern'"
pdftotext -q ./test PDF file 1.pdf - | grep --with-filename --label='['./test PDF file 1.pdf']' --color=always --ignore-case --context=5 'pattern'
pdftotext -q ./subdir1/test PDF file 2.pdf - | grep --with-filename --label='['./subdir1/test PDF file 2.pdf']' --color=always --ignore-case --context=5 'pattern'
pdftotext -q ./subdir2/test PDF file 3.pdf - | grep --with-filename --label='['./subdir2/test PDF file 3.pdf']' --color=always --ignore-case --context=5 'pattern'
- luttztfz
-1
使用pdfgrep。
在这个命令中,我正在文件夹
如您在输出中所见,您可以获得带有行号的文件名:
pdfgrep -HinR 'FWCOSP' DatenModel/
在这个命令中,我正在文件夹
DatenModel/中搜索单词FWCOSP。如您在输出中所见,您可以获得带有行号的文件名:
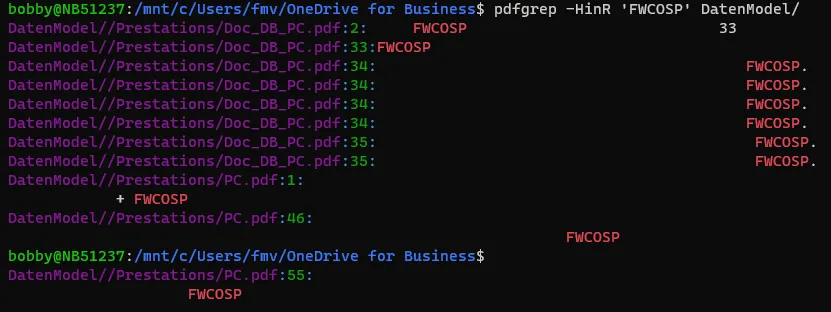
我正在使用的选项是:
-i : Ignores, case for matching
-H : print the file name for each match
-n : prefix each match with the number of the page where it is found
-R : same as -r, but it also follows all symlinks.
- Francesco Mantovani
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接