我正在进行一个学校项目,其中有几个PDF文件。我想要添加一个按姓名搜索的功能,只需输入学生的姓名,就可以打开所有与其姓名相关的PDF文件。最好的方法是什么?我在网上寻找解决方案,但只找到了iTextSharp,它让我更加困惑了。
这是否可行?也许有人可以给我一个教程链接或其他东西。 :) 非常感谢。
这是否可行?也许有人可以给我一个教程链接或其他东西。 :) 非常感谢。
http://sourceforge.net/projects/itextsharp/
这里是一个简单的函数,用于从PDF中读取文本。Public Shared Function GetTextFromPDF(PdfFileName As String) As String
Dim oReader As New iTextSharp.text.pdf.PdfReader(PdfFileName)
Dim sOut = ""
For i = 1 To oReader.NumberOfPages
Dim its As New iTextSharp.text.pdf.parser.SimpleTextExtractionStrategy
sOut &= iTextSharp.text.pdf.parser.PdfTextExtractor.GetTextFromPage(oReader, i, its)
Next
Return sOut
End Function
PDF是非常复杂的规范,可能会创建许多变体,除非使用创建它的相同工具读取它(即使使用相同工具,通常也无法可靠解析)。有几个工具可以将PDF压缩成文本字符串(例如pdf2text),并且可能可以搜索这些内容,但这样做不可靠。
许多PDF工具只实现了规范的一部分。有些人建议最好的搜索PDF的方法是将其转换为图像,然后进行OCR。
根据您的系统,此任务可能很简单。
对于Windows用户工作站或数据库服务器,您可以使用具有缓存索引的iFilter,这将成为随着时间推移最快的方法。
传统上,Acrobat会在内部索引多个文件:
如果您处理大量相关的PDF文件,可以在Acrobat Pro中将它们定义为目录,从而为PDF文件生成PDF索引。搜索PDF索引而不是PDF本身可以显著加快搜索速度。
在Windows上,您可以安装任何iFilter并使用Windows本机文件搜索,甚至无需Pro或Acrobat,只需搜索栏,它也可以比完整的慢速搜索更快。
或者有许多应用程序可以混合搜索包含文本字符串的PDF文件,其中一些还可以缓存结果以供以后使用。请参见诸如Everything(未索引)或AgentRansack(已索引)之类的工具。
没有iFilter的系统需要采用不同的方法。
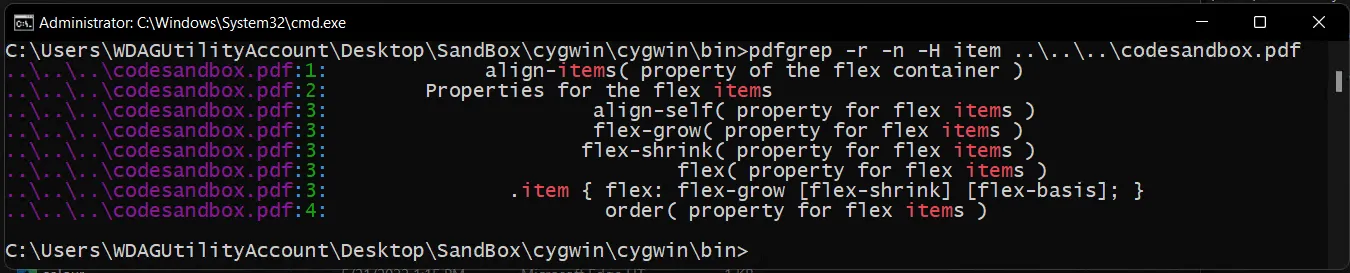
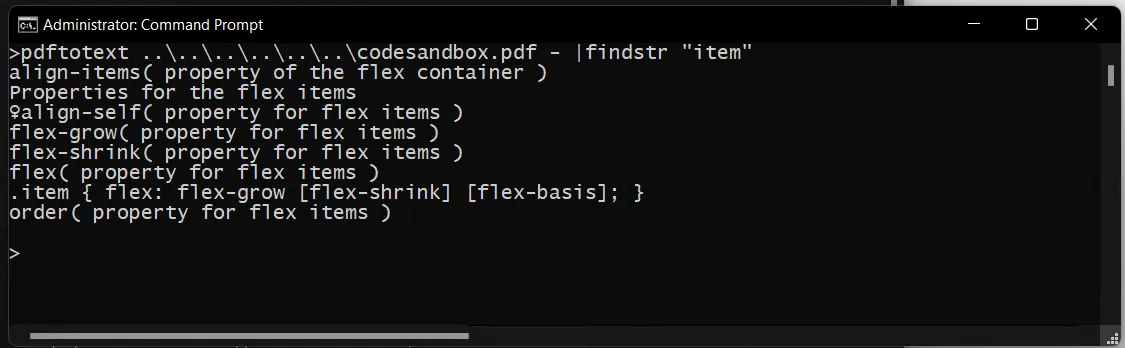
但是对于一个小的PDF语料库,最简单的跨平台调用程序是使用特定于操作系统的管道循环遍历目录或文件列表,并使用pdftotext进行转换。
Install-Package IKVM -Version 8.2.0
下载所需的jar文件并在项目中引用它们:
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<OutputType>Exe</OutputType>
<TargetFramework>net6.0</TargetFramework>
<ImplicitUsings>disable</ImplicitUsings>
<Nullable>disable</Nullable>
</PropertyGroup>
<ItemGroup>
<PackageReference Include="IKVM" Version="8.2.0" />
</ItemGroup>
<ItemGroup>
<IkvmReference Include="commons-logging-1.2.jar" />
<IkvmReference Include="fontbox-3.0.0-alpha3.jar" >
<References>commons-logging-1.2.jar</References>
</IkvmReference>
<IkvmReference Include="pdfbox-3.0.0-alpha3.jar" >
<References>commons-logging-1.2.jar;fontbox-3.0.0-alpha3.jar</References>
</IkvmReference>
</ItemGroup>
</Project>
然后在C#中使用PDFBox:
using org.apache.pdfbox.io;
using org.apache.pdfbox.pdfparser;
using org.apache.pdfbox.text;
public class Program
{
public static string getTextFromPdf(string pdfPath)
{
using(var input = new RandomAccessReadBufferedFile(pdfPath))
{
var parser = new PDFParser(input);
var pdDoc = parser.parse();
var pdfStripper = new PDFTextStripper();
return pdfStripper.getText(pdDoc);
}
}
public static void Main(string[] args)
{
var res = getTextFromPdf(@"C:\Temp\test.pdf");
System.Console.WriteLine(res);
}
}