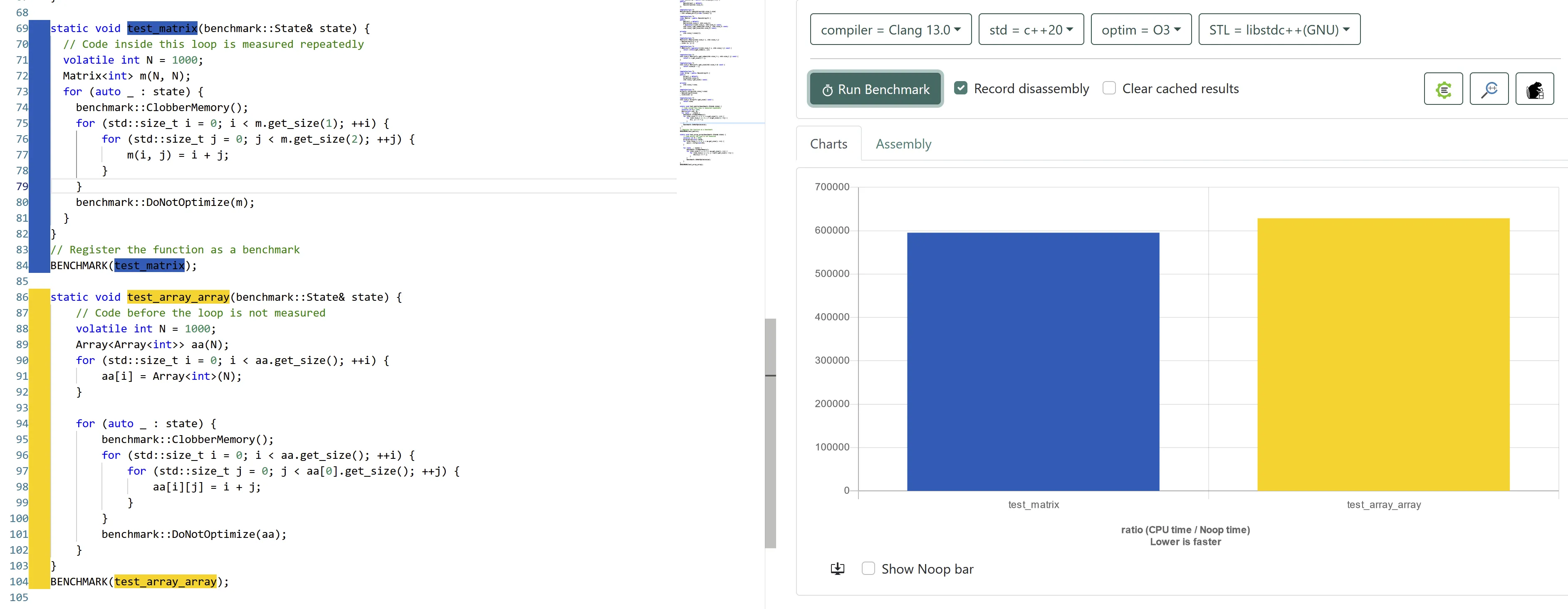
我一直认为,只需要通过乘法一次索引的多维数组比通过两个指针解除引用进行索引的数组更快,因为前者具有更好的局部性和空间节省。
不久前,我进行了一项小测试,结果相当令人惊讶。至少我的callgrind分析器报告说,使用数组的相同函数运行速度略快。
我想知道是否应该更改我的矩阵类的定义,以在内部使用数组。这个类在我的仿真引擎中被几乎所有地方使用,我确实希望找到最好的方法来节省几秒钟。
test_matrix的成本为350 200 020,test_array_array的成本为325 200 016。代码是由clang++编译的,并且根据分析器,所有成员函数都已经被内联。
#include <iostream>
#include <memory>
template<class T>
class BasicArray : public std::unique_ptr<T[]> {
public:
BasicArray() = default;
BasicArray(std::size_t);
};
template<class T>
BasicArray<T>::BasicArray(std::size_t size)
: std::unique_ptr<T[]>(new T[size]) {}
template<class T>
class Matrix : public BasicArray<T> {
public:
Matrix() = default;
Matrix(std::size_t, std::size_t);
T &operator()(std::size_t, std::size_t) const;
std::size_t get_index(std::size_t, std::size_t) const;
std::size_t get_size(std::size_t) const;
private:
std::size_t sizes[2];
};
template<class T>
Matrix<T>::Matrix(std::size_t i, std::size_t j)
: BasicArray<T>(i * j)
, sizes {i, j} {}
template<class T>
T &Matrix<T>::operator()(std::size_t i, std::size_t j) const {
return (*this)[get_index(i, j)];
}
template<class T>
std::size_t Matrix<T>::get_index(std::size_t i, std::size_t j) const {
return i * get_size(2) + j;
}
template<class T>
std::size_t Matrix<T>::get_size(std::size_t d) const {
return sizes[d - 1];
}
template<class T>
class Array : public BasicArray<T> {
public:
Array() = default;
Array(std::size_t);
std::size_t get_size() const;
private:
std::size_t size;
};
template<class T>
Array<T>::Array(std::size_t size)
: BasicArray<T>(size)
, size(size) {}
template<class T>
std::size_t Array<T>::get_size() const {
return size;
}
static void __attribute__((noinline)) test_matrix(const Matrix<int> &m) {
for (std::size_t i = 0; i < m.get_size(1); ++i) {
for (std::size_t j = 0; j < m.get_size(2); ++j) {
static_cast<volatile void>(m(i, j) = i + j);
}
}
}
static void __attribute__((noinline))
test_array_array(const Array<Array<int>> &aa) {
for (std::size_t i = 0; i < aa.get_size(); ++i) {
for (std::size_t j = 0; j < aa[0].get_size(); ++j) {
static_cast<volatile void>(aa[i][j] = i + j);
}
}
}
int main() {
constexpr int N = 1000;
Matrix<int> m(N, N);
Array<Array<int>> aa(N);
for (std::size_t i = 0; i < aa.get_size(); ++i) {
aa[i] = Array<int>(N);
}
test_matrix(m);
test_array_array(aa);
}