我正试图更好地理解CPU缓存如何影响性能。作为一个简单的测试,我正在对一个带有不同总列数的矩阵的第一列的值进行求和。
// compiled with: gcc -Wall -Wextra -Ofast -march=native cache.c
// tested with: for n in {1..100}; do ./a.out $n; done | tee out.csv
#include <assert.h>
#include <stdint.h>
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
double sum_column(uint64_t ni, uint64_t nj, double const data[ni][nj])
{
double sum = 0.0;
for (uint64_t i = 0; i < ni; ++i) {
sum += data[i][0];
}
return sum;
}
int compare(void const* _a, void const* _b)
{
double const a = *((double*)_a);
double const b = *((double*)_b);
return (a > b) - (a < b);
}
int main(int argc, char** argv)
{
// set sizes
assert(argc == 2);
uint64_t const iter_max = 101;
uint64_t const ni = 1000000;
uint64_t const nj = strtol(argv[1], 0, 10);
// initialize data
double(*data)[nj] = calloc(ni, sizeof(*data));
for (uint64_t i = 0; i < ni; ++i) {
for (uint64_t j = 0; j < nj; ++j) {
data[i][j] = rand() / (double)RAND_MAX;
}
}
// test performance
double* dt = calloc(iter_max, sizeof(*dt));
double const sum0 = sum_column(ni, nj, data);
for (uint64_t iter = 0; iter < iter_max; ++iter) {
clock_t const t_start = clock();
double const sum = sum_column(ni, nj, data);
clock_t const t_stop = clock();
assert(sum == sum0);
dt[iter] = (t_stop - t_start) / (double)CLOCKS_PER_SEC;
}
// sort dt
qsort(dt, iter_max, sizeof(*dt), compare);
// compute mean dt
double dt_mean = 0.0;
for (uint64_t iter = 0; iter < iter_max; ++iter) {
dt_mean += dt[iter];
}
dt_mean /= iter_max;
// print results
printf("%2lu %.8e %.8e %.8e %.8e\n", nj, dt[iter_max / 2], dt_mean, dt[0],
dt[iter_max - 1]);
// free memory
free(data);
}
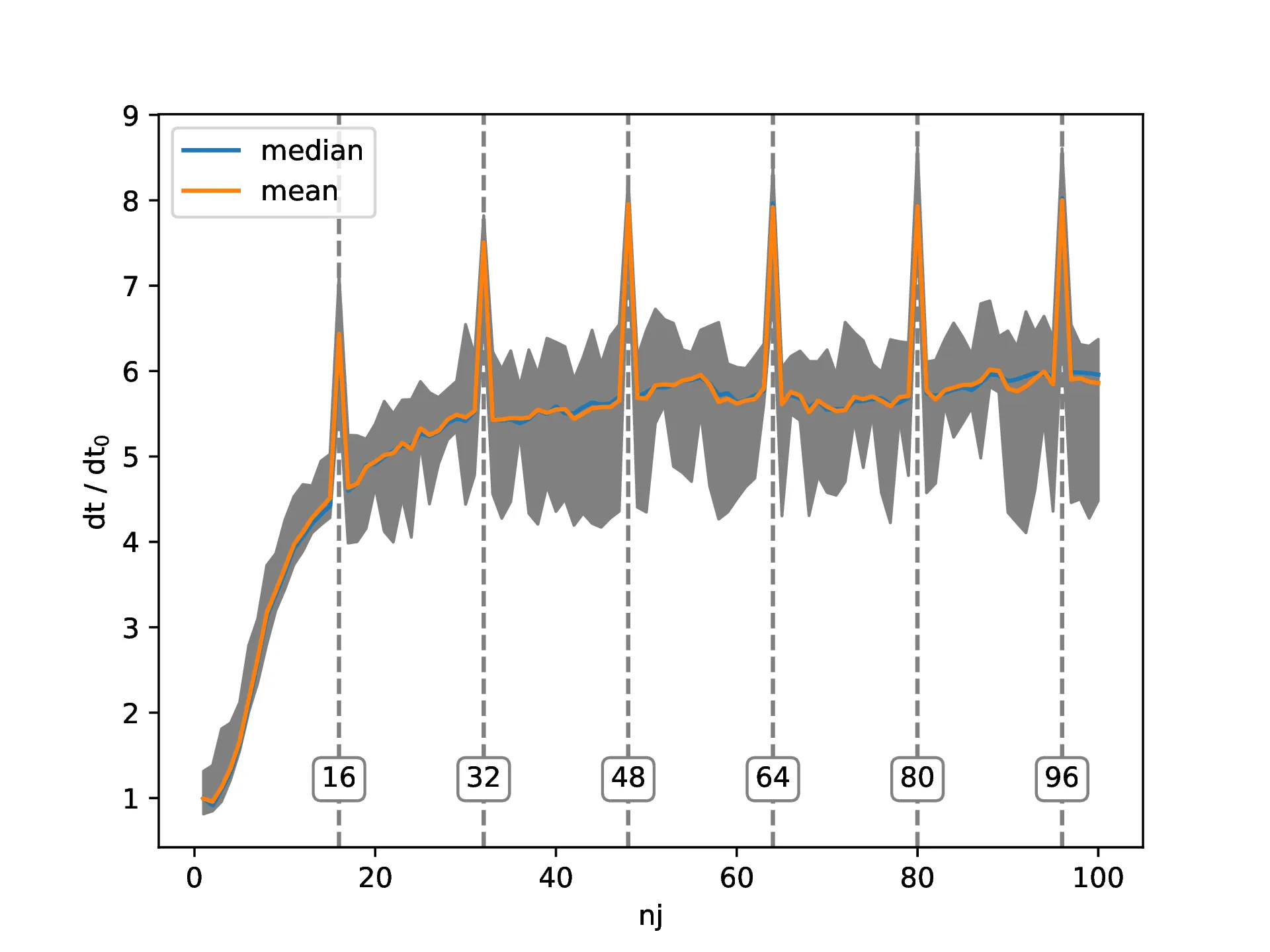 据我所知,当CPU从"data"中加载一个值时,它还会将"data"的一些后续值放入缓存中。确切的数量取决于缓存行大小(在我的机器上为64字节)。这就可以解释为什么随着
据我所知,当CPU从"data"中加载一个值时,它还会将"data"的一些后续值放入缓存中。确切的数量取决于缓存行大小(在我的机器上为64字节)。这就可以解释为什么随着nj的增长,解决方案的时间首先线性增加,然后在某个值上趋于稳定。如果nj == 1,则一次加载将把下一个7个值放入缓存中,因此我们只需要每8个值从RAM中加载一次。如果nj == 2,根据相同的逻辑,我们需要每4个值访问一次RAM。在某个尺寸之后,我们将不得不为每个值访问RAM,这应该导致性能趋于平稳。我猜测,为什么图表的线性部分超过了4,是因为实际上有多个级别的缓存在这里起作用,值如何进入这些缓存的方式比我在这里解释的要复杂一些。我无法解释的是为什么有这些16的倍数性能峰值。在思考了一会儿这个问题之后,我决定检查是否对于更高的nj值也会出现这种情况: 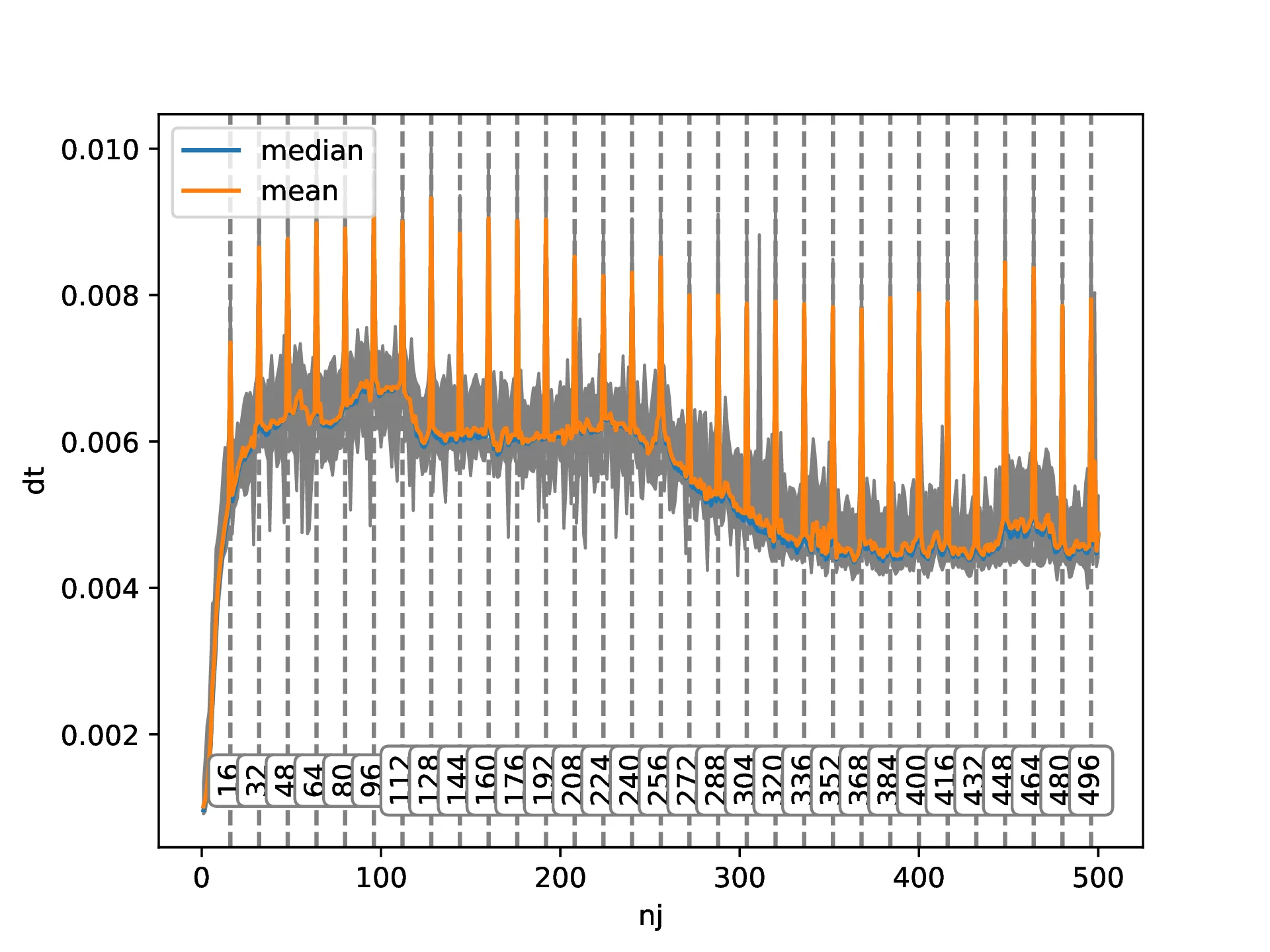 实际上,确实如此。并且,还有更多:为什么在大约250之后性能又会提高?有人能向我解释一下,或者指点我一些适当的参考资料,为什么会出现这些峰值以及为什么在较高的
实际上,确实如此。并且,还有更多:为什么在大约250之后性能又会提高?有人能向我解释一下,或者指点我一些适当的参考资料,为什么会出现这些峰值以及为什么在较高的nj值时性能会提高吗?如果您想自己尝试代码,我也会附上我的绘图脚本,以方便您使用:import numpy as np
import matplotlib.pyplot as plt
data = np.genfromtxt("out.csv")
data[:,1:] /= data[0,1]
dy = np.diff(data[:,2]) / np.diff(data[:,0])
for i in range(len(dy) - 1):
if dy[i] - dy[i + 1] > (dy.max() - dy.min()) / 2:
plt.axvline(data[i + 1,0], color='gray', linestyle='--')
plt.text(data[i + 1,0], 1.5 * data[0,3], f"{int(data[i + 1,0])}",
rotation=0, ha="center", va="center",
bbox=dict(boxstyle="round", ec='gray', fc='w'))
plt.fill_between(data[:,0], data[:,3], data[:,4], color='gray')
plt.plot(data[:,0], data[:,1], label="median")
plt.plot(data[:,0], data[:,2], label="mean")
plt.legend(loc="upper left")
plt.xlabel("nj")
plt.ylabel("dt / dt$_0$")
plt.savefig("out.pdf")
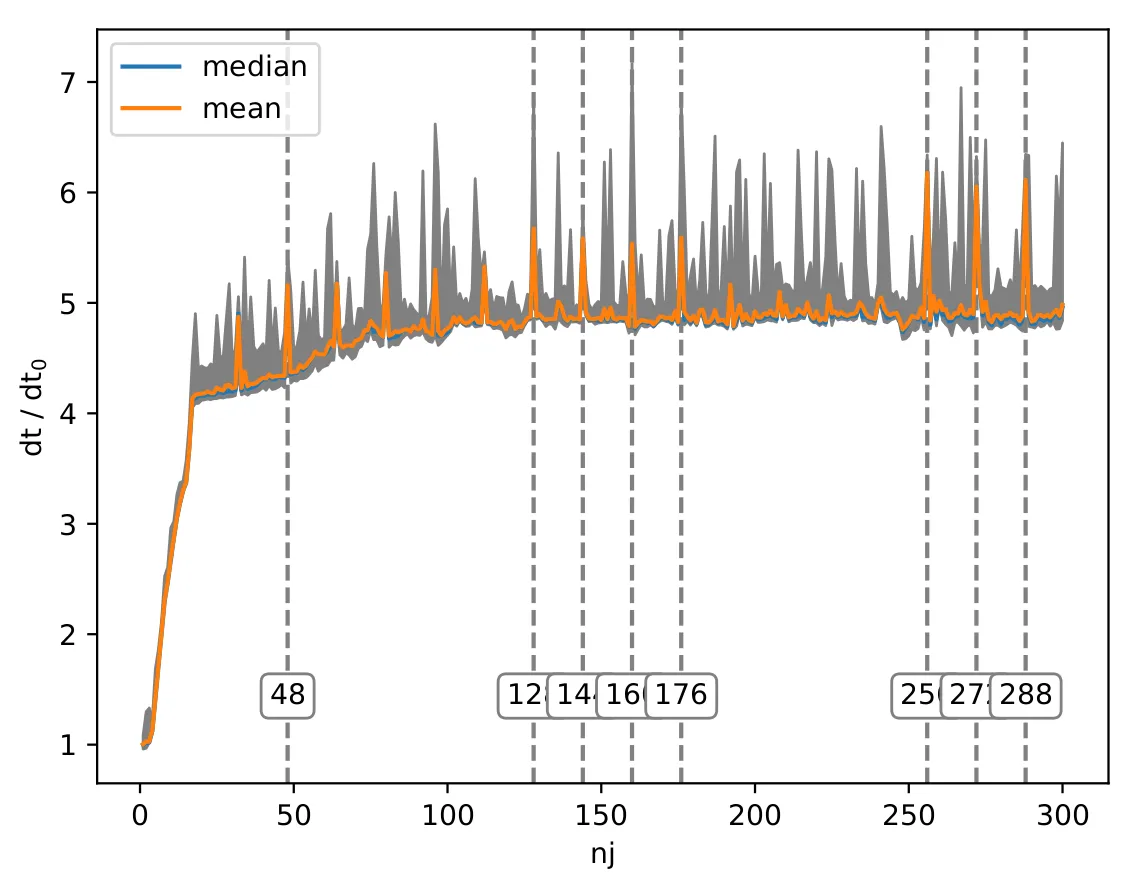
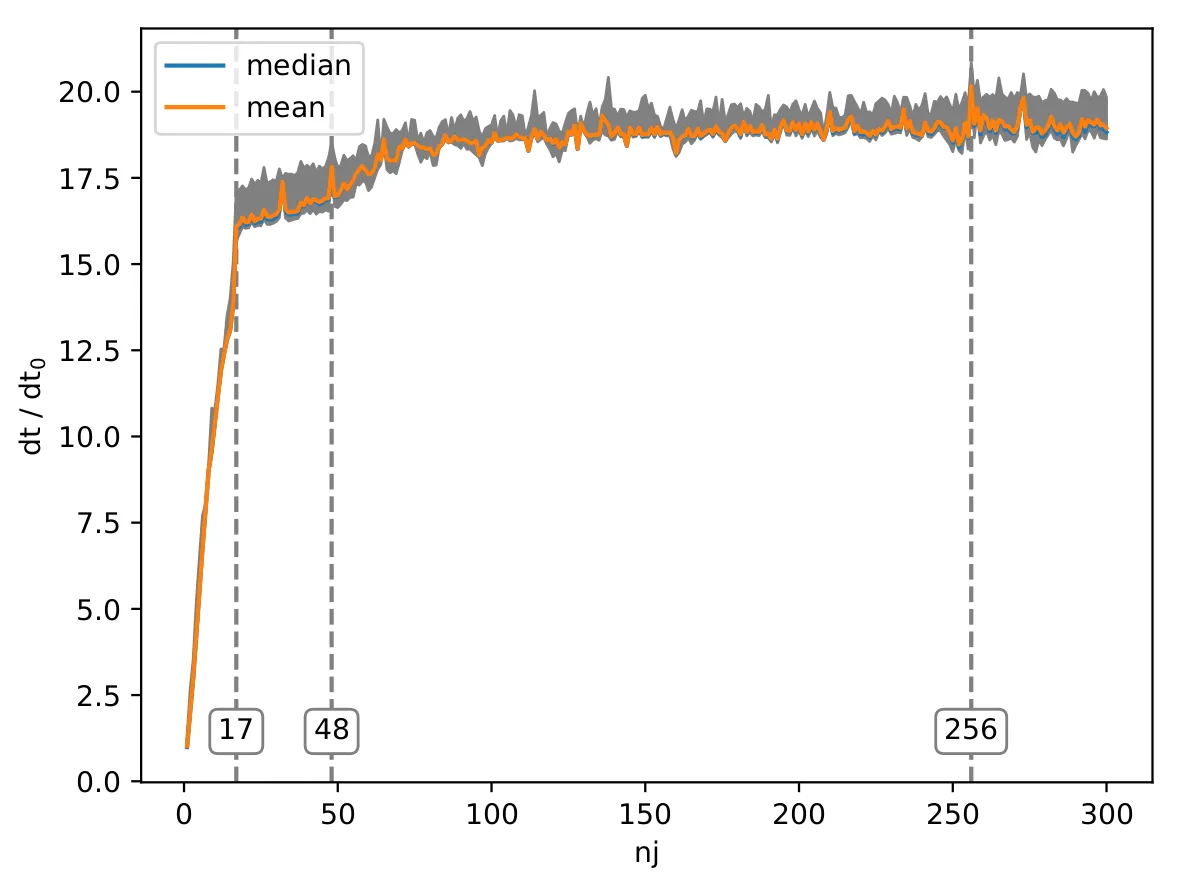
data中加载一个值时,它还会将data的一些后续值放入缓存。”这是不正确的。当启用缓存时进行加载时,CPU会加载数据所在的缓存块(或者如果跨越边界,则为两个缓存块)。如果数据位于块的开头,则确实会加载其他数据。如果数据位于块的中间或末尾,则可能会加载之前的数据或替代它。 - Eric Postpischilnj是16的倍数时,您的加载方式会跳过一些缓存集,从而跳过了一些缓存集。因此,您只能使用大约一半的缓存。 - Eric Postpischilnj的值不是16的倍数时,负载将通过不同的高速缓存集合进行处理。我还没有分析您的代码以确定这种特定效果是否是原因。 - Eric Postpischildouble时,它不仅会将8个字节加载到缓存中,而且会将通常为64个字节的整个缓存行加载到缓存中,其中可能包括double之前和之后的数据。2. 如果CPU检测到顺序访问模式,它将根据预测预取数据。 - Andreas Wenzel