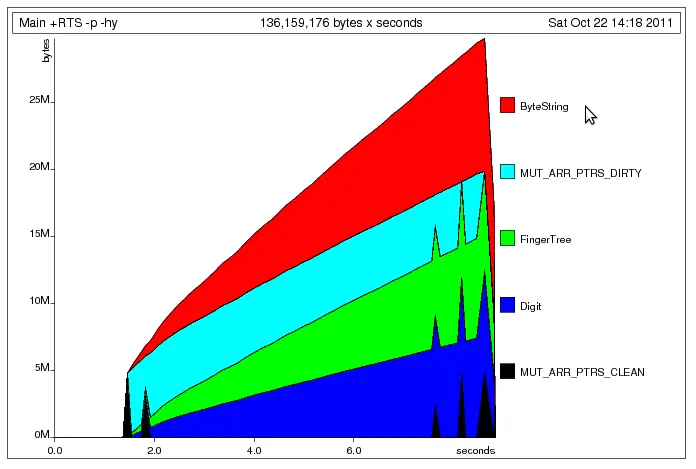
在我对一些用于将推文数据分解为n元组的Haskell代码进行了最后一次性能优化之后,我遇到了一个空间泄漏的问题。当我进行性能分析时,GC使用了大约60-70%的进程,并且有很多内存被拖累。希望一些Haskell大牛能够指出我的错误所在。
{-# LANGUAGE OverloadedStrings, BangPatterns #-}
import Data.Maybe
import qualified Data.ByteString.Char8 as B
import qualified Data.HashMap.Strict as H
import Text.Regex.Posix
import Data.List
import qualified Data.Char as C
isClassChar a = C.isAlphaNum a || a == ' ' || a == '\'' ||
a == '-' || a == '#' || a == '@' || a == '%'
cullWord :: B.ByteString -> B.ByteString
cullWord w = B.map C.toLower $ B.filter isClassChar w
procTextN :: Int -> B.ByteString -> [([B.ByteString],Int)]
procTextN n t = H.toList $ foldl' ngram H.empty lines
where !lines = B.lines $ cullWord t
ngram tr line = snd $ foldl' breakdown (base,tr) (B.split ' ' line)
base = replicate (n-1) ""
breakdown :: ([B.ByteString], H.HashMap [B.ByteString] Int) -> B.ByteString -> ([B.ByteString],H.HashMap [B.ByteString] Int)
breakdown (st@(s:ss),tree) word =
newStack `seq` expandedWord `seq` (newStack,expandedWord)
where newStack = ss ++ [word]
expandedWord = updateWord (st ++ [word]) tree
updateWord :: [B.ByteString] -> H.HashMap [B.ByteString] Int -> H.HashMap [B.ByteString] Int
updateWord w h = H.insertWith (+) w 1 h
main = do
test2 <- B.readFile "canewobble"
print $ filter (\(a,b) -> b > 100) $
sortBy (\(a,b) (c,d) -> compare d b) $ procTextN 3 test2
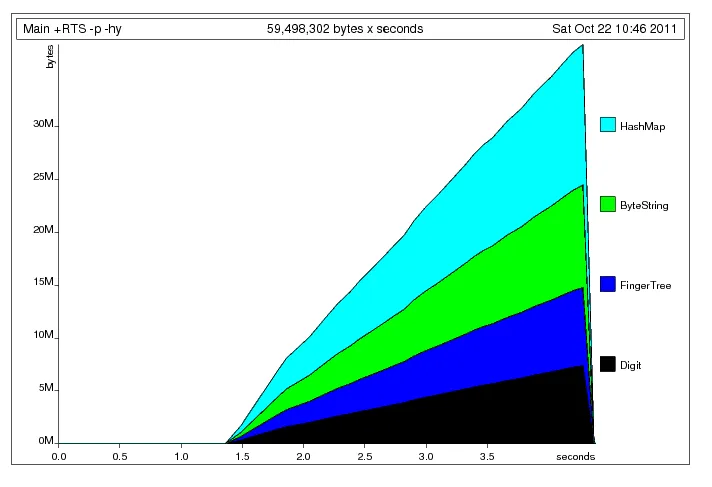 。
。
procTextN上,移除sortBy并没有太大帮助。 - Mikhail GlushenkovB.ByteString和H.HashMap(像这样:import Data.HashMap.Strict(HashMap)除了你现在有的限定导入之外),那会帮助很多。 - HaskellElephant