现在我有一个数据框和两个列表,每个列表包含一些数据框列名,我需要添加新的列,其中包含数据框中每列的排名。问题是我必须按照 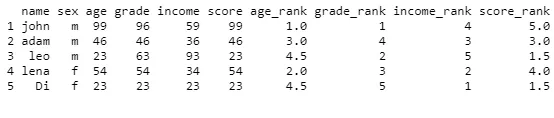 我尝试了使用
我尝试了使用
Deslist1 列表中的列降序排列,并按与 Asclist1 匹配的列名升序排列。相应地,最终所需的输出结果如下:
我尝试了使用 any() 和 within() 但它们不起作用。我的问题不是如何添加包含排名的新列,而是如何基于列表元素进行排名,正如您可以看到 Asclist1 包含的元素不存在于 DF1 列中。DF1 <- data.frame("name" = c("john", "adam", "leo", "lena", "Di"),
"sex" = c("m", "m", "m", "f", "f"),
"age" = c(99, 46, 23, 54, 23),
"grade" = c(96, 46, 63, 54, 23),
"income" = c(59, 36, 93, 34, 23),
"score" = c(99, 46, 23, 54, 23))
print(DF1)
Asclist1<-list("score","income","spending")
Asclist1
Deslist2<-list("age","grade")
Deslist2
更新——代码1
library(readr)
library(tidyr)
library(purrr)
library(rlang)
library(glue)
library(dplyr)
library(miscTools)
library(matrixStats)
library(shiny)
library(reshape2)
library(dplyr)
hotdrinks<-list("tea","green tea")
juices<-list("orange","mango")
energydrinks<-list("powerhorse","redbull")
drinks<-list("hotdrinks"=hotdrinks,"juices"=juices,"energydrinks"=energydrinks)
biscuits<-list("loacker","tuc")
choc<-list("aftereight","lindt")
gum<-list("trident","clortes")
sweets<-list("gum"=gum,"biscuits"=biscuits,"choc"=choc)
all_products<-list("sweets"=sweets,"drinks"=drinks)
mt<-melt(all_products)
mt2<-mt%>%mutate("Price"=c(23,34,23,23,54,32,45,23,12,56,76,43),
"Quantity"=c(10,20,26,22,51,52,45,23,12,56,76,43),
"amount"=c(23,34,23,23,54,32,45,23,12,56,76,43))
t1<-mt2[,c(4,3,1,5,6,7)]
t1
colnames(t1)<-c("CAT","PN","SP","Quantity","Price","amount")
t2<-list(unique(t1$CAT))
t2
QL<-c("Quantity","Price")
QD<-c("Quantity","amount")
QS<-c("amount","Price")
all <- list("drinks"=drinks, "sweets"=sweets)
FCX<-data.frame("sbo"=c("w","q","a"),
"Quantity_fcx"=c(3,2,5),
"Price_fcx"=c(7,8,5),
"amount_fcx"=c(4,7,3)
)
#DF1<-Y
DF1 <- t1
DF1
#print(DF1)
DFCXL<-list(colnames(DF1[-c(1:3)]))
DFCXL
DFCX1<-lapply(DFCXL, paste0, "_fcx")
DFCX1
DFCXM<-colMeans(FCX[,unlist(DFCX1)],na.rm = FALSE)
DFCXM
DFCXMd<-colMedians(data.matrix(FCX[,unlist(DFCX1)]),na.rm = FALSE )
DFCXMddf<-as.data.frame(t(DFCXMd))
DFCXMddf
DFCX1l<-as.list(DFCX1)
colnames(DFCXMddf)<-unlist(DFCX1l)
DFCXMddf
#median repeated tibble
rDFCXMddf<-DFCXMddf[rep(seq_len(nrow(DFCXMddf)), each = nrow(DF1)), ]
rDFCXMddf
DFCX<-data.frame(t(DFCXM))
DFL<-as.vector(colnames(DF1))
DFL
DFCX
#mean repeated tibble
rDFCX<-DFCX[rep(seq_len(nrow(DFCX)), each = nrow(DF1)), ]
#rDFCX
#ascending rank form smallest to largest where the smallest is the most competitive
Asclist1<-list("Quantity","Price")
#Asclist1
#descending rank form largest to smallest where the largest is the most competitive
Deslist2<-list("xyz","amount")
#Deslist2
#DF3 contains orginal dataframe with rank for each column descending & ascending
DF3<-
DF1 %>% mutate_if(grepl(paste(Deslist2, collapse = "|"), names(.)), list(rank=~rank(-.))) %>%
mutate_if(grepl(paste(Asclist1, collapse = "|"), names(.)), list(rank=~rank( .)))
DF3
#DF4 contains only determinants columns
DF4<-DF3%>%select(-one_of(DFL))
DF4
#DF5 contains all deterements with their ranks columns
DF5<-cbind(rDFCX,DF4)
DF5
#getting final rank for each column based on multiplying CX columns "weight" * normal rank to get weighted ranking
dynamic_mutate = function(DF5,
col_names = gsub("(.*)_\\w+$", "\\1", names(DF5)),
expression = "({x}_rank*{x}_fcx)",
prefix = "FINAL"){
name_list = col_names %>% unique() %>% as.list()
expr_list = name_list %>% lapply(function(x) parse_quosure(glue(expression))) %>%
setNames(paste(prefix, name_list, sep = "_"))
DF5 %>% mutate(!!!expr_list)}
DF6<-DF5 %>% dynamic_mutate()
#DF6
#getting mean for ranks
DFL2<-as.vector(colnames(DF5))
DF7<-DF6%>%select(-one_of(DFL2))
#DF7
#final limit ranking
DF8<-mutate(DF7,fnl_scr=rowMeans(DF7))
#DF8
#final rank
Ranking<-rank(DF8$fnl_scr)
#Ranking
#final dataframe
DF9<-as_tibble(cbind(DF1,Ranking))
DF9
代码 2
library(readr)
library(tidyr)
library(purrr)
library(rlang)
library(glue)
library(dplyr)
library(miscTools)
library(matrixStats)
library(shiny)
library(reshape2)
library(dplyr)
hotdrinks<-list("tea","green tea")
juices<-list("orange","mango")
energydrinks<-list("powerhorse","redbull")
drinks<-list("hotdrinks"=hotdrinks,"juices"=juices,"energydrinks"=energydrinks)
biscuits<-list("loacker","tuc")
choc<-list("aftereight","lindt")
gum<-list("trident","clortes")
sweets<-list("gum"=gum,"biscuits"=biscuits,"choc"=choc)
all_products<-list("sweets"=sweets,"drinks"=drinks)
mt<-melt(all_products)
mt2<-mt%>%mutate("Price"=c(23,34,23,23,54,32,45,23,12,56,76,43),
"Quantity"=c(10,20,26,22,51,52,45,23,12,56,76,43),
"amount"=c(23,34,23,23,54,32,45,23,12,56,76,43))
t1<-mt2[,c(4,3,1,5,6,7)]
t1
colnames(t1)<-c("CAT","PN","SP","Quantity","Price","amount")
t2<-list(unique(t1$CAT))
t2
QL<-c("Quantity","Price")
QD<-c("Quantity","amount")
QS<-c("amount","Price")
all <- list("drinks"=drinks, "sweets"=sweets)
FCX<-data.frame("sbo"=c("w","q","a"),
"Quantity_fcx"=c(3,2,5),
"Price_fcx"=c(7,8,5),
"amount_fcx"=c(4,7,3)
)
#DF1<-Y
DF1 <- t1
DF1
#print(DF1)
DFCXL<-list(colnames(DF1[-c(1:3)]))
DFCXL
DFCX1<-lapply(DFCXL, paste0, "_fcx")
DFCX1
DFCXM<-colMeans(FCX[,unlist(DFCX1)],na.rm = FALSE)
DFCXM
DFCXMd<-colMedians(data.matrix(FCX[,unlist(DFCX1)]),na.rm = FALSE )
DFCXMddf<-as.data.frame(t(DFCXMd))
DFCXMddf
DFCX1l<-as.list(DFCX1)
colnames(DFCXMddf)<-unlist(DFCX1l)
DFCXMddf
#median repeated tibble
rDFCXMddf<-DFCXMddf[rep(seq_len(nrow(DFCXMddf)), each = nrow(DF1)), ]
rDFCXMddf
DFCX<-data.frame(t(DFCXM))
DFL<-as.vector(colnames(DF1))
DFL
DFCX
#mean repeated tibble
rDFCX<-DFCX[rep(seq_len(nrow(DFCX)), each = nrow(DF1)), ]
#rDFCX
#ascending rank form smallest to largest where the smallest is the most competitive
Asclist1<-list("Quantity","Price","amount")
#Asclist1
#descending rank form largest to smallest where the largest is the most competitive
Deslist2<-list("xyz")
#Deslist2
#DF3 contains orginal dataframe with rank for each column descending & ascending
DF3<-
DF1 %>% mutate_if(grepl(paste(Deslist2, collapse = "|"), names(.)), list(rank=~rank(-.))) %>%
mutate_if(grepl(paste(Asclist1, collapse = "|"), names(.)), list(rank=~rank( .)))
DF3
#DF4 contains only determinants columns
DF4<-DF3%>%select(-one_of(DFL))
DF4
#DF5 contains all deterements with their ranks columns
DF5<-cbind(rDFCX,DF4)
DF5
#getting final rank for each column based on multiplying CX columns "weight" * normal rank to get weighted ranking
dynamic_mutate = function(DF5,
col_names = gsub("(.*)_\\w+$", "\\1", names(DF5)),
expression = "({x}_rank*{x}_fcx)",
prefix = "FINAL"){
name_list = col_names %>% unique() %>% as.list()
expr_list = name_list %>% lapply(function(x) parse_quosure(glue(expression))) %>%
setNames(paste(prefix, name_list, sep = "_"))
DF5 %>% mutate(!!!expr_list)}
DF6<-DF5 %>% dynamic_mutate()
#DF6
#getting mean for ranks
DFL2<-as.vector(colnames(DF5))
DF7<-DF6%>%select(-one_of(DFL2))
#DF7
#final limit ranking
DF8<-mutate(DF7,fnl_scr=rowMeans(DF7))
#DF8
#final rank
Ranking<-rank(DF8$fnl_scr)
#Ranking
#final dataframe
DF9<-as_tibble(cbind(DF1,Ranking))
DF9