我知道如何在Keras中编写具有其他输入的自定义损失函数,而不是标准的
我的解决方法是:
以下是我的解决方法的示例代码:(是的,我知道这是一个非常愚蠢的自定义损失函数,在现实中情况要复杂得多)。
y_true和y_pred对。我的问题是使用一个可训练变量(其中一些是损失梯度的一部分并应进行更新)来输入损失函数。我的解决方法是:
- 输入一个大小为
NXV的虚拟输入,其中N是观测值数量,V是附加变量数量 - 添加
Dense()层dummy_output,以便Keras会跟踪我的V“权重” - 在我的真实输出层中使用这个层的
V权重作为自定义损失函数 - 对于这个
dummy_output层使用虚拟损失函数(仅返回0.0和/或权重为0.0),以便我的V“权重”只通过我的自定义损失函数进行更新
以下是我的解决方法的示例代码:(是的,我知道这是一个非常愚蠢的自定义损失函数,在现实中情况要复杂得多)。
import numpy as np
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
from tensorflow.keras.layers import Dense
from tensorflow.keras.callbacks import EarlyStopping
import tensorflow.keras.backend as K
from tensorflow.keras.layers import Input
from tensorflow.keras import Model
n_col = 10
n_row = 1000
X = np.random.normal(size=(n_row, n_col))
beta = np.arange(10)
y = X @ beta
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# my custom loss function accepting my dummy layer with 2 variables
def custom_loss_builder(dummy_layer):
def custom_loss(y_true, y_pred):
var1 = dummy_layer.trainable_weights[0][0]
var2 = dummy_layer.trainable_weights[0][1]
return var1 * K.mean(K.square(y_true-y_pred)) + var2 ** 2 # so var2 should get to zero, var1 should get to minus infinity?
return custom_loss
# my dummy loss function
def dummy_loss(y_true, y_pred):
return 0.0
# my dummy input, N X V, where V is 2 for 2 vars
dummy_x_train = np.random.normal(size=(X_train.shape[0], 2))
# model
inputs = Input(shape=(X_train.shape[1],))
dummy_input = Input(shape=(dummy_x_train.shape[1],))
hidden1 = Dense(10)(inputs) # here only 1 hidden layer in the "real" network, assume whatever network is built here
output = Dense(1)(hidden1)
dummy_output = Dense(1, use_bias=False)(dummy_input)
model = Model(inputs=[inputs, dummy_input], outputs=[output, dummy_output])
# compilation, notice zero loss for the dummy_output layer
model.compile(
loss=[custom_loss_builder(model.layers[-1]), dummy_loss],
loss_weights=[1.0, 0.0], optimizer= 'adam')
# run, notice y_train repeating for dummy_output layer, it will not be used, could have created dummy_y_train as well
history = model.fit([X_train, dummy_x_train], [y_train, y_train],
batch_size=32, epochs=100, validation_split=0.1, verbose=0,
callbacks=[EarlyStopping(monitor='val_loss', patience=5)])
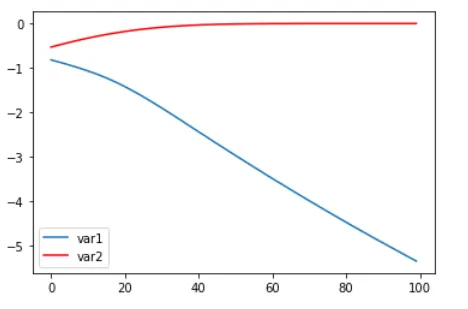
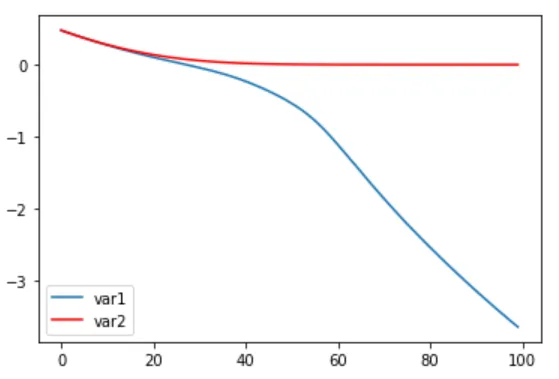
看起来无论 var1 和 var2(初始化 dummy_output 层)的起始值是什么,它似乎都能渐进地达到负无穷和 0:
(此图来自迭代运行该模型并保存这两个权重的结果,如下所示)
var1_list = []
var2_list = []
for i in range(100):
if i % 10 == 0:
print('step %d' % i)
model.fit([X_train, dummy_x_train], [y_train, y_train],
batch_size=32, epochs=1, validation_split=0.1, verbose=0)
var1, var2 = model.layers[-1].get_weights()[0]
var1_list.append(var1.item())
var2_list.append(var2.item())
plt.plot(var1_list, label='var1')
plt.plot(var2_list, 'r', label='var2')
plt.legend()
plt.show()