我从pandas DataFrame文档开始:数据结构介绍
我想要以时间序列的方式逐步填充DataFrame的值。我想要用列A、B和时间戳行来初始化DataFrame,全部为0或NaN。
然后,我会添加初始值,并通过对数据进行计算,从前一行计算出新的行,比如说
目前我正在使用下面的代码,但是我觉得它有点丑陋,肯定有一种直接使用DataFrame或者更好的方法。
然后,我会添加初始值,并通过对数据进行计算,从前一行计算出新的行,比如说
row[A][t] = row[A][t-1]+1之类的操作。目前我正在使用下面的代码,但是我觉得它有点丑陋,肯定有一种直接使用DataFrame或者更好的方法。
import pandas as pd
import datetime as dt
import scipy as s
base = dt.datetime.today().date()
dates = [ base - dt.timedelta(days=x) for x in range(9, -1, -1) ]
valdict = {}
symbols = ['A','B', 'C']
for symb in symbols:
valdict[symb] = pd.Series( s.zeros(len(dates)), dates )
for thedate in dates:
if thedate > dates[0]:
for symb in valdict:
valdict[symb][thedate] = 1 + valdict[symb][thedate - dt.timedelta(days=1)]
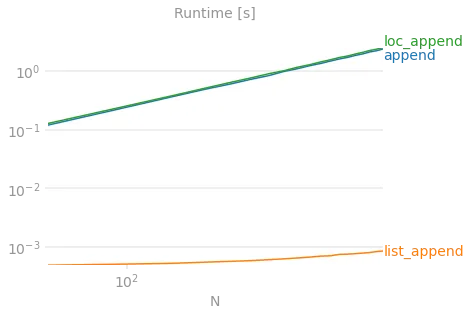
.append和在 Python 中使用列表添加之间的功能区别是什么?我知道 pandas 中的.append会将整个数据集复制到一个新对象中,那么 Python 的append是否有不同的工作方式呢? - Lamma