import pandas as pd
import numpy as np
from datetime import datetime
df = pd.DataFrame(
{
'Date' : np.random.choice(pd.date_range(datetime(2020,1,1),periods=5),20),
'Product' : np.random.choice(['Milk','Brandy','Beer'],20) ,
'Quantity' : np.random.randint(10,99,20)
}
)
df.groupby(['Date','Product']).sum()
这将给出:
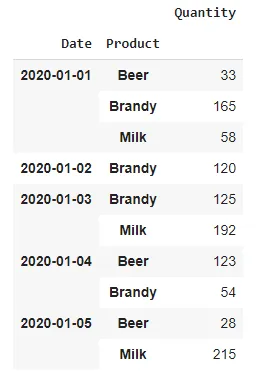
我想要获得每组总和的最大值,有什么最好的方法吗?
我的随机样本值的预期结果如下。
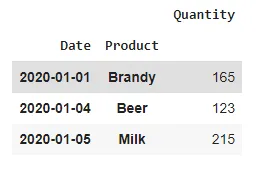
我该如何实现这个结果。