我正在寻找一个可以用来确定给定数据库中是否有任何数据(即行数)的SQL脚本。
这个想法是在存在任何行(在任何数据库中)的情况下重新创建数据库。
所讨论的数据库是Microsoft SQL Server。
有人可以提供一个示例脚本吗?
我正在寻找一个可以用来确定给定数据库中是否有任何数据(即行数)的SQL脚本。
这个想法是在存在任何行(在任何数据库中)的情况下重新创建数据库。
所讨论的数据库是Microsoft SQL Server。
有人可以提供一个示例脚本吗?
以下 SQL 将获取数据库中所有表的行数:
CREATE TABLE #counts
(
table_name varchar(255),
row_count int
)
EXEC sp_MSForEachTable @command1='INSERT #counts (table_name, row_count) SELECT ''?'', COUNT(*) FROM ?'
SELECT table_name, row_count FROM #counts ORDER BY table_name, row_count DESC
DROP TABLE #counts
SELECT SUM(row_count) AS total_row_count FROM #counts
这将为您获取整个数据库中行的总数的单个值。
sp_MSForEachTable是一个未公开的存储过程。据我所知,这意味着微软不支持它,并且可能在未来版本中没有通知地将其删除。 - MarkD如果您想绕过计算3百万行表格的时间和资源,请尝试以下SQL SERVER Central by Kendal Van Dyke中提到的方法。
使用sysindexes进行行计数 如果您正在使用SQL 2000,则需要像这样使用sysindexes:
-- Shows all user tables and row counts for the current database
-- Remove OBJECTPROPERTY function call to include system objects
SELECT o.NAME,
i.rowcnt
FROM sysindexes AS i
INNER JOIN sysobjects AS o ON i.id = o.id
WHERE i.indid < 2 AND OBJECTPROPERTY(o.id, 'IsMSShipped') = 0
ORDER BY o.NAME
如果你使用的是SQL 2005或者2008,查询sysindexes仍然可以工作,但是微软建议在未来的SQL Server版本中可能会删除sysindexes,所以作为良好的实践,你应该使用DMVs代替,像这样:
-- Shows all user tables and row counts for the current database
-- Remove is_ms_shipped = 0 check to include system objects
-- i.index_id < 2 indicates clustered index (1) or hash table (0)
SELECT o.name,
ddps.row_count
FROM sys.indexes AS i
INNER JOIN sys.objects AS o ON i.OBJECT_ID = o.OBJECT_ID
INNER JOIN sys.dm_db_partition_stats AS ddps ON i.OBJECT_ID = ddps.OBJECT_ID
AND i.index_id = ddps.index_id
WHERE i.index_id < 2 AND o.is_ms_shipped = 0 ORDER BY o.NAME
JOIN sys.schemas s ON s.schema_id = o.schema_id并包含了s.Name来查看有资格的表名。 - Bernhard Hofmann可以在Azure上使用,不需要存储过程。
SELECT t.name AS table_name
,s.row_count AS row_count
FROM sys.tables t
JOIN sys.dm_db_partition_stats s
ON t.OBJECT_ID = s.OBJECT_ID
AND t.type_desc = 'USER_TABLE'
AND t.name NOT LIKE '%dss%' --Exclude tables created by SQL Data Sync for Azure.
AND s.index_id IN (0, 1)
ORDER BY table_name;
USE [enter your db name here]
GO
SELECT SCHEMA_NAME(A.schema_id) + '.' +
--A.Name, SUM(B.rows) AS 'RowCount' Use AVG instead of SUM
A.Name, AVG(B.rows) AS 'RowCount'
FROM sys.objects A
INNER JOIN sys.partitions B ON A.object_id = B.object_id
WHERE A.type = 'U'
GROUP BY A.schema_id, A.Name
GO
data_reader权限,因此其他解决方案对我无效 - 只有这个有效。 - Ed Grahamsp_MSForEachTable 'DECLARE @t AS VARCHAR(MAX);
SELECT @t = CAST(COUNT(1) as VARCHAR(MAX))
+ CHAR(9) + CHAR(9) + ''?'' FROM ? ; PRINT @t'
输出:
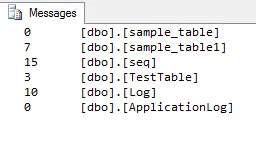
SELECT COUNT(1) FROM ?是一个资源密集型的操作所导致的。 - undefinedSELECT
sc.name +'.'+ ta.name TableName, SUM(pa.rows) RowCnt
FROM
sys.tables ta
INNER JOIN sys.partitions pa
ON pa.OBJECT_ID = ta.OBJECT_ID
INNER JOIN sys.schemas sc
ON ta.schema_id = sc.schema_id
WHERE ta.is_ms_shipped = 0 AND pa.index_id IN (1,0)
GROUP BY sc.name,ta.name
ORDER BY SUM(pa.rows) DESC
SQL Server 2005或更高版本提供了一个很好的报告,显示表大小 - 包括行计数等。它在标准报告中 - 名为“按表格使用磁盘空间”。
通过编程实现,可以使用一个优雅的解决方案,详见: http://www.sqlservercentral.com/articles/T-SQL/67624/
SELECT COUNT(*) FROM TABLENAME,因为这是一个资源密集型操作。我们可以使用 SQL Server Dynamic Management Views 或 System Catalogs 来获取数据库中所有表的行数信息。请注意优化查询性能。这里有一种动态SQL的方法,同时还提供了模式:
DECLARE @sql nvarchar(MAX)
SELECT
@sql = COALESCE(@sql + ' UNION ALL ', '') +
'SELECT
''' + s.name + ''' AS ''Schema'',
''' + t.name + ''' AS ''Table'',
COUNT(*) AS Count
FROM ' + QUOTENAME(s.name) + '.' + QUOTENAME(t.name)
FROM sys.schemas s
INNER JOIN sys.tables t ON t.schema_id = s.schema_id
ORDER BY
s.name,
t.name
EXEC(@sql)
sys.databases)。
声明c_tables游标快速向前
选择表名from information_schema.tables
打开c_tables
声明@tablename varchar(255)
声明@stmt nvarchar(2000)
声明@rowcount int
获取下一个@c_tables到@tablename
while @@fetch_status = 0
begin
选择@stmt = 'sp_spaceused ' + @tablename
执行sp_executesql @stmt
获取下一个@c_tables到@tablename
end
关闭c_tables
取消分配c_tables