它似乎可以同时用于三元和普通的if语句。
首先,让我们看一下以下三个代码示例,其中两个在普通if和三元if样式中都使用了 __builtin_expect ,而第三个则完全没有使用。
builtin.c:
int main()
{
char c = getchar();
const char *printVal;
if (__builtin_expect(c == 'c', 1))
{
printVal = "Took expected branch!\n";
}
else
{
printVal = "Boo!\n";
}
printf(printVal);
}
ternary.c:
int main()
{
char c = getchar();
const char *printVal = __builtin_expect(c == 'c', 1)
? "Took expected branch!\n"
: "Boo!\n";
printf(printVal);
}
nobuiltin.c:
int main()
{
char c = getchar();
const char *printVal;
if (c == 'c')
{
printVal = "Took expected branch!\n";
}
else
{
printVal = "Boo!\n";
}
printf(printVal);
}
当使用-O3编译时,这三个代码生成的汇编代码是相同的。但是,当省略-O(在GCC 4.7.2上)时,无论是ternary.c还是builtin.c在关键位置都具有相同的汇编代码:
builtin.s:
.file "builtin.c"
.section .rodata
.LC0:
.string "Took expected branch!\n"
.LC1:
.string "Boo!\n"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
pushl %ebp
.cfi_def_cfa_offset 8
.cfi_offset 5, -8
movl %esp, %ebp
.cfi_def_cfa_register 5
andl $-16, %esp
subl $32, %esp
call getchar
movb %al, 27(%esp)
cmpb $99, 27(%esp)
sete %al
movzbl %al, %eax
testl %eax, %eax
je .L2
movl $.LC0, 28(%esp)
jmp .L3
.L2:
movl $.LC1, 28(%esp)
.L3:
movl 28(%esp), %eax
movl %eax, (%esp)
call printf
leave
.cfi_restore 5
.cfi_def_cfa 4, 4
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (Debian 4.7.2-4) 4.7.2"
.section .note.GNU-stack,"",@progbits
ternary.s:
.file "ternary.c"
.section .rodata
.LC0:
.string "Took expected branch!\n"
.LC1:
.string "Boo!\n"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
pushl %ebp
.cfi_def_cfa_offset 8
.cfi_offset 5, -8
movl %esp, %ebp
.cfi_def_cfa_register 5
andl $-16, %esp
subl $32, %esp
call getchar
movb %al, 31(%esp)
cmpb $99, 31(%esp)
sete %al
movzbl %al, %eax
testl %eax, %eax
je .L2
movl $.LC0, %eax
jmp .L3
.L2:
movl $.LC1, %eax
.L3:
movl %eax, 24(%esp)
movl 24(%esp), %eax
movl %eax, (%esp)
call printf
leave
.cfi_restore 5
.cfi_def_cfa 4, 4
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (Debian 4.7.2-4) 4.7.2"
.section .note.GNU-stack,"",@progbits
相比之下,nobuiltin.c并不会:
.file "nobuiltin.c"
.section .rodata
.LC0:
.string "Took expected branch!\n"
.LC1:
.string "Boo!\n"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
pushl %ebp
.cfi_def_cfa_offset 8
.cfi_offset 5, -8
movl %esp, %ebp
.cfi_def_cfa_register 5
andl $-16, %esp
subl $32, %esp
call getchar
movb %al, 27(%esp)
cmpb $99, 27(%esp)
jne .L2
movl $.LC0, 28(%esp)
jmp .L3
.L2:
movl $.LC1, 28(%esp)
.L3:
movl 28(%esp), %eax
movl %eax, (%esp)
call printf
leave
.cfi_restore 5
.cfi_def_cfa 4, 4
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (Debian 4.7.2-4) 4.7.2"
.section .note.GNU-stack,"",@progbits
相关部分:
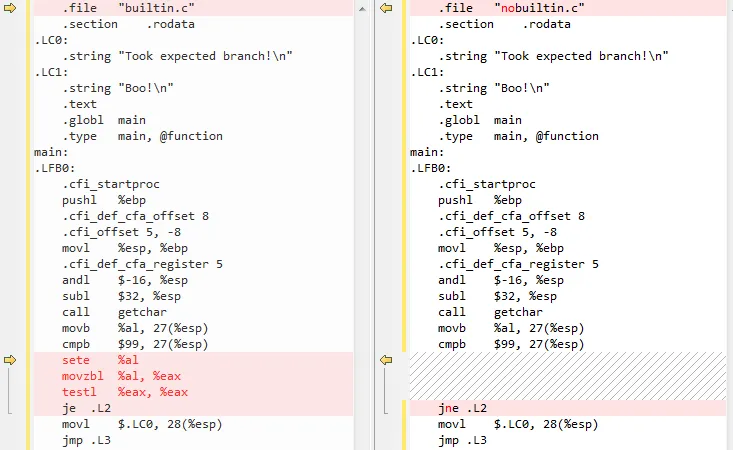
基本上,__builtin_expect 会导致额外的代码(例如 sete %al ...)在根据CPU更有可能预测为1(这里是一种天真的假设)而不是基于输入字符与 'c' 的直接比较之前执行。然而,在nobuiltin.c中,没有这样的代码存在,je/jne 直接跟随与 'c' 的比较(cmp $99)。请记住,分支预测主要由CPU完成,在这里GCC只是为CPU分支预测器“设置陷阱”,以假定将采取哪个路径(通过额外的代码和 je 和 jne 的切换,尽管我没有来源证实这一点,因为英特尔的官方优化手册没有提到将首次遇到的 je 与 jne 与分支预测不同对待!我只能推断GCC团队通过试错得出了这一结论)。
我相信有更好的测试用例可以更直接地看到GCC的分支预测(而不是观察CPU的提示),但我不知道如何简洁地模拟这样的情况。(猜测:在编译期间可能涉及循环展开。)
__builtin_expect对于x86优化代码没有影响(因为你说它们在-O3下是相同的)之外的任何内容。它们之前唯一不同的原因是__builtin_expect是一个返回给定值的函数,而该返回值不能通过标志发生。否则,差异将保留在优化代码中。 - ughoavgfhwsete %al。它是内置函数,返回比较结果。 - ughoavgfhw__builtin_expect在这样一个简单的代码片段上可能是无操作(根据您的代码经验而言)。特别是在 x86 上。您应该尝试一些代码片段,其中不太可能执行许多其他指令的代码路径,并查看编译器是否足够聪明,将其移出热路径。(在 x86 上,分支预测器非常好,使用__builtin_expect的唯一原因是缩小热路径的 icache 占用空间。)您还可以尝试为 ARM 或 PPC 编译,这更有可能具有专门用于欺骗分支预测器的特殊编译器逻辑。 - Quuxplusone