以下这些不同类型的字节序是什么区别?
- 字节(8位)不变的大端和小端字节序
- 半字(16位)不变的大端和小端字节序
- 字(32位)不变的大端和小端字节序
- 双字(64位)不变的大端和小端字节序
是否存在其他类型或变化的字节序?
以下这些不同类型的字节序是什么区别?
是否存在其他类型或变化的字节序?
对于字节序映射,有两种方法:地址不变和数据不变。
在这种类型的映射中,字节的地址在大端和小端之间始终保持不变。这会导致特定数据(例如2或4字节的单词)的重要性顺序(从最高位到最低位)被反转,因此数据的解释也随之改变。具体而言,在小端中,数据的解释为最不重要的字节到最重要的字节,而在大端中,解释为最重要的字节到最不重要的字节。在两种情况下,访问的字节集保持不变。
示例
地址不变(也称为字节不变):字节地址是固定的,但字节的重要性被颠倒。
Addr Memory
7 0
| | (LE) (BE)
|----|
+0 | aa | lsb msb
|----|
+1 | bb | : :
|----|
+2 | cc | : :
|----|
+3 | dd | msb lsb
|----|
| |
At Addr=0: Little-endian Big-endian
Read 1 byte: 0xaa 0xaa (preserved)
Read 2 bytes: 0xbbaa 0xaabb
Read 4 bytes: 0xddccbbaa 0xaabbccdd
在这种映射类型中,特定大小的数据的相对字节重要性得以保留。因此,对于不同的数据大小,会有不同类型的数据不变性端序映射。例如,对于32位数据,将使用32位字不变性端序映射。保留特定大小数据的值的效果是,在大端和小端映射之间翻转数据内部字节的地址。
示例
32位数据不变性(也称为“字不变性”):数据是一个32位字,其值始终为0xddccbbaa,与端序无关。然而,对于小于一个字的访问,字节的地址在大端和小端映射之间被颠倒。
Addr Memory
| +3 +2 +1 +0 | <- LE
|-------------------|
+0 msb | dd | cc | bb | aa | lsb
|-------------------|
+4 msb | 99 | 88 | 77 | 66 | lsb
|-------------------|
BE -> | +0 +1 +2 +3 |
At Addr=0: Little-endian Big-endian
Read 1 byte: 0xaa 0xdd
Read 2 bytes: 0xbbaa 0xddcc
Read 4 bytes: 0xddccbbaa 0xddccbbaa (preserved)
Read 8 bytes: 0x99887766ddccbbaa 0x99887766ddccbbaa (preserved)
例子
16位数据不变性(也称为半字不变性):该数据是一个16位值,始终具有0xbbaa的值,与大小端无关。但是,对于小于半字的访问,字节的地址在大端和小端的映射之间被颠倒。
Addr Memory
| +1 +0 | <- LE
|---------|
+0 msb | bb | aa | lsb
|---------|
+2 msb | dd | cc | lsb
|---------|
+4 msb | 77 | 66 | lsb
|---------|
+6 msb | 99 | 88 | lsb
|---------|
BE -> | +0 +1 |
At Addr=0: Little-endian Big-endian
Read 1 byte: 0xaa 0xbb
Read 2 bytes: 0xbbaa 0xbbaa (preserved)
Read 4 bytes: 0xddccbbaa 0xddccbbaa (preserved)
Read 8 bytes: 0x99887766ddccbbaa 0x99887766ddccbbaa (preserved)
示例
64位数据不变性(也称为双字不变性):该数据是一个64位字,其值始终为0x99887766ddccbbaa,独立于字节序。但是,对于小于双字的访问,字节的地址在大端和小端映射之间被颠倒。
Addr Memory
| +7 +6 +5 +4 +3 +2 +1 +0 | <- LE
|---------------------------------------|
+0 msb | 99 | 88 | 77 | 66 | dd | cc | bb | aa | lsb
|---------------------------------------|
BE -> | +0 +1 +2 +3 +4 +5 +6 +7 |
At Addr=0: Little-endian Big-endian
Read 1 byte: 0xaa 0x99
Read 2 bytes: 0xbbaa 0x9988
Read 4 bytes: 0xddccbbaa 0x99887766
Read 8 bytes: 0x99887766ddccbbaa 0x99887766ddccbbaa (preserved)
我怀疑任何体系结构都不会破坏字节值不变性。当映射包含它们的结构体时,位字段的顺序可能需要反转。这种直接映射依赖于编译器的细节,这些细节超出了C99标准,但仍然可能是常见的。直接映射更快,但不符合C99标准,该标准不规定打包、对齐和字节顺序。符合C99标准的代码应该使用基于值而非地址的慢速映射。也就是说,不要像这样做:比特实际上被反转了。
#if LITTLE_ENDIAN
struct breakdown_t {
int least_significant_bit: 1;
int middle_bits: 10;
int most_significant_bits: 21;
};
#elif BIG_ENDIAN
struct breakdown_t {
int most_significant_bits: 21;
int middle_bits: 10;
int least_significant_bit: 1;
};
#else
#error Huh
#endif
uint32_t data = ...;
struct breakdown_t *b = (struct breakdown_t *)&data;
应该这样编写代码(即使对于上面的“直接映射”,编译器也会生成相同的代码),
uint32_t data = ...;
uint32_t least_significant_bit = data & 0x00000001;
uint32_t middle_bits = (data >> 1) & 0x000003FF;
uint32_t most_significant_bits = (data >> 11) & 0x001fffff;
还有一种中间或混合字节序。详情请看维基百科。
唯一需要担心这个问题的时候是在使用C语言编写网络代码时。据我所知,网络通常使用大端序。但是大多数语言要么完全抽象化这个问题,要么提供库来保证您使用正确的字节序。
0x100: 12 34 56 78 90 ab cd ef
Reads Little Endian Big Endian
8-bit: 12 12
16-bit: 34 12 12 34
32-bit: 78 56 34 12 12 34 56 78
64-bit: ef cd ab 90 78 56 34 12 12 34 56 78 90 ab cd ef
你需要注意大小端的两种情况是网络编程和在使用指针进行下行转换时。
TCP/IP规定,网络传输数据应该采用大端字节序。如果你传输除了字节数组以外的类型(比如结构体指针),你需要确保使用ntoh/hton宏来保证数据被发送为大端字节序。如果你从一个小端处理器发送到一个大端处理器(或者反过来),数据将会变得混乱...
转换问题:
uint32_t* lptr = 0x100;
uint16_t data;
*lptr = 0x0000FFFF
data = *((uint16_t*)lptr);
data的值将是多少? 在大端系统上,它将为0,在小端系统上,它将为FFFF
实际上,我会将机器的字节序描述为单词内部字节的顺序,而不是位的顺序。
在上面的“字节”中,我指的是“体系结构可以单独管理的最小存储单位”。因此,如果最小单位长度为16位(在x86中称为word),则表示值0xFFFF0000的32位“word”可以像这样存储:
FFFF 0000
或者这样:
0000 FFFF
在内存中,取决于字节序。
因此,如果您的字节序为8位,则表示由16位组成的每个单词将被存储为:
FF 00
或者:
00 FF
等等。
FFFF0000 示例选择不恰当,因为如果您按位、字节或字方式颠倒它,则会变成 0000FFFF,因此无法确定您想要表达什么! - Scott Griffiths正如@erik-van-brakel在此帖子中所回答的那样,在与某些PLC通信时要小心:混合字节序仍然存在!
事实上,我需要使用(Modbus-TCP) OPC协议与一款PLC(来自知名制造商)进行通信,似乎每个半字都返回给我一个混合字节序。因此,一些大型制造商仍在使用它。
这里是一个“pieces”字符串的示例:
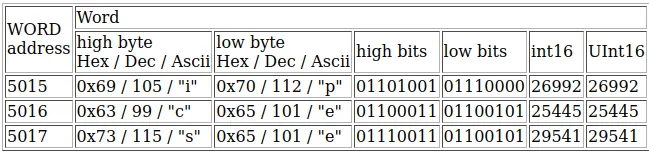
13年前,我曾经开发过一款可以在DEC ALPHA系统和PC上运行的工具。在这个DEC ALPHA系统上,位实际上是反转的。也就是说:
1010 0011
实际上被翻译为
1100 0101
这段代码几乎在C语言中是透明且无缝的,除了我有一个位域(bitfield)声明如下:
typedef struct {
int firstbit:1;
int middlebits:10;
int lastbits:21;
};
需要翻译成(使用 #ifdef 条件编译)
typedef struct {
int lastbits:21;
int middlebits:10;
int firstbit:1;
};
基本概念是比特的排序:
1010 0011
小端序与
是相同的。0011 1010
在大端序(和小端序)中。
你会注意到顺序是通过分组而不是单个位来改变的。例如,我不知道有哪个系统可以
1100 0101
将是第一个版本的“另一端”版本。