这是之前提出问题的编辑版本。
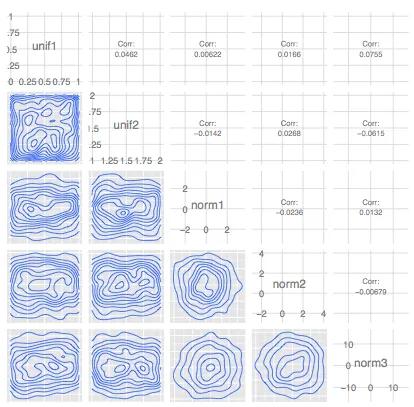
我们有一个 m × n 的表格,其中包含 m 个变量(如基因等)的 n 个观测值(样本),我们希望研究每两个观测值之间变量的行为 - 比如具有最高正相关或负相关的两个观测值。为此,我在 Stadler et.al. 自然杂志论文 (2011) 中看到了一张很棒的图表: 这里可以使用以下示例数据集。
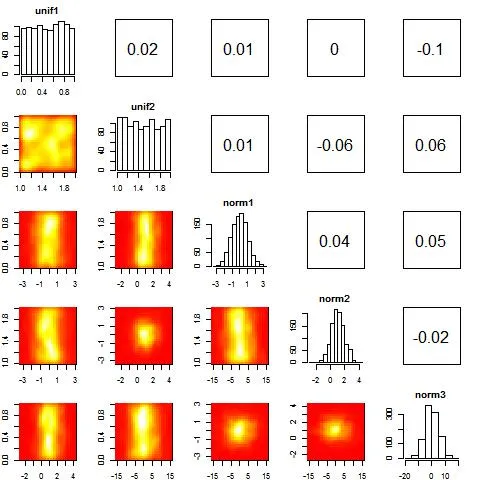
我已经测试了包
我们有一个 m × n 的表格,其中包含 m 个变量(如基因等)的 n 个观测值(样本),我们希望研究每两个观测值之间变量的行为 - 比如具有最高正相关或负相关的两个观测值。为此,我在 Stadler et.al. 自然杂志论文 (2011) 中看到了一张很棒的图表: 这里可以使用以下示例数据集。
m <- 1000
samples <- data.frame(unif1 = runif(m), unif2 = runif(m, 1, 2), norm1 = rnorm(m),
norm2 = rnorm(m, 1), norm3 = rnorm(m, 0, 5))
我已经测试了包
gpairs 中的 gpairs(samples) 函数,生成了如下的散点矩阵图。这是一个好的开始,但它没有将相关系数放在右上角,也没有在左下角显示密度图:
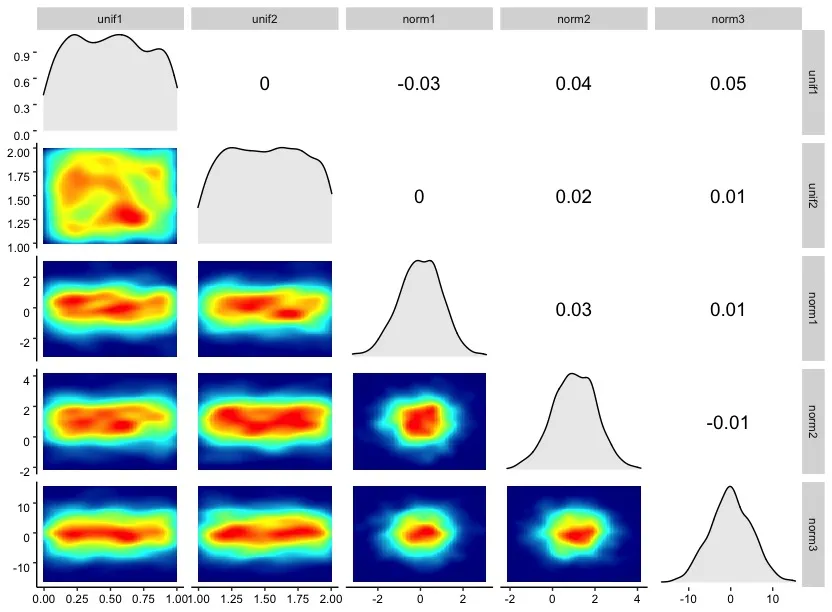
GGally 包中的 ggpairs(samples, lower=list(continuous="density")) 函数(感谢 @LucianoSelzer 的评论)。现在我们在右上角有了相关性信息,在左下角显示了密度图,但我们缺少对角线条形图,而密度图不是热力图形状。