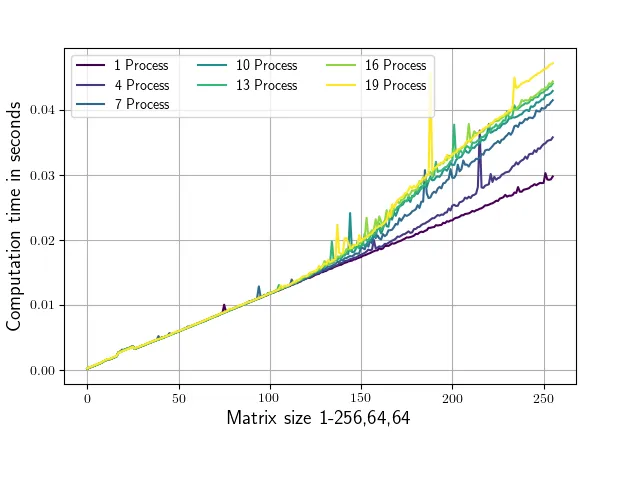
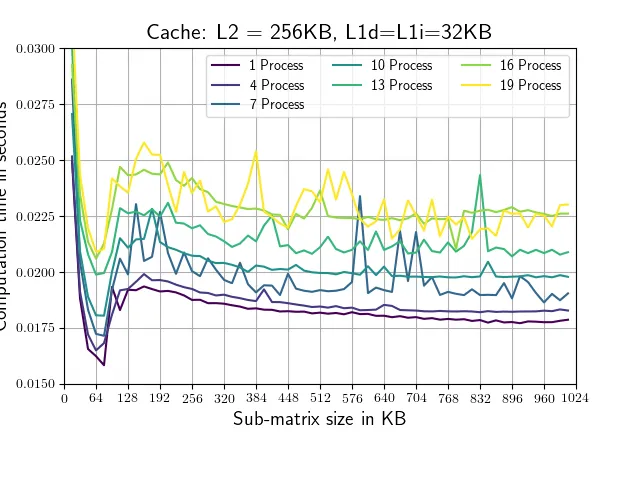
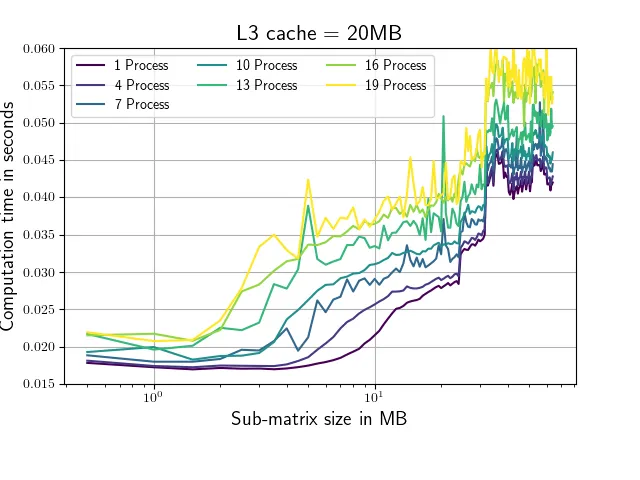
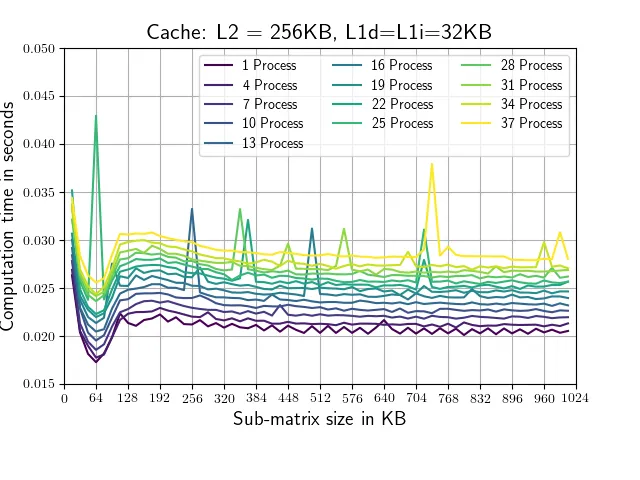
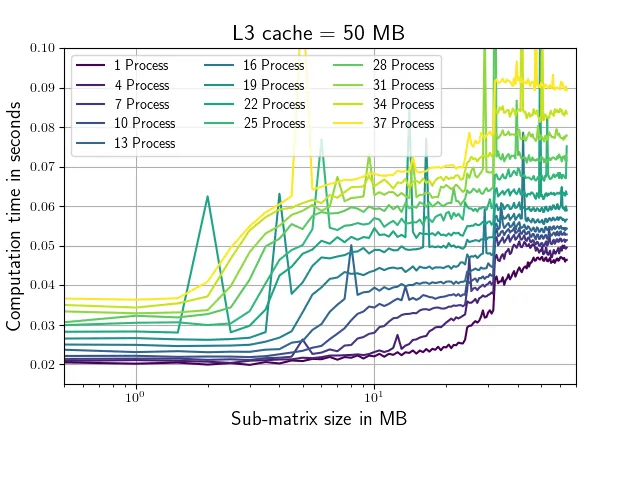
这个脚本评估了numpy.conjugate例程在不同大小的矩阵上使用不同数量并行进程的运行时间,并记录相应的运行时间。矩阵形状仅在其第一维(从1,64,64到256,64,64)上有所变化。共轭调用始终在1,64,64子矩阵上进行,以确保正在处理的部分适合我的系统中的L2缓存(每个核心256 KB,我的情况下是25MB的L3缓存)。运行该脚本会产生以下图表(带有略有不同的轴标签和颜色)。
from multiprocessing import Process, Queue
import time
import numpy as np
import os
from matplotlib import pyplot as plt
os.environ['OPENBLAS_NUM_THREADS'] = '1'
os.environ['MKL_NUM_THREADS'] = '1'
def f(q,size):
a = np.random.rand(size,64,64) + 1.j*np.random.rand(size,64,64)
start = time.time()
n=a.shape[0]
for i in range(20):
for b in a:
b.conj()
duration = time.time()-start
q.put(duration)
def speed_test(number_of_processes=1,size=1):
number_of_processes = number_of_processes
process_list=[]
queue = Queue()
#Start processes
for p_id in range(number_of_processes):
p = Process(target=f,args=(queue,size))
process_list.append(p)
p.start()
#Wait until all processes are finished
for p in process_list:
p.join()
output = []
while queue.qsize() != 0:
output.append(queue.get())
return np.mean(output)
if __name__ == '__main__':
processes=np.arange(1,20,3)
data=[[] for i in processes]
for p_id,p in enumerate(processes):
for size_0 in range(1,257):
data[p_id].append(speed_test(number_of_processes=p,size=size_0))
fig,ax = plt.subplots()
for d in data:
ax.plot(d)
ax.set_xlabel('Matrix Size: 1-256,64,64')
ax.set_ylabel('Runtime in seconds')
fig.savefig('result.png')
q.put可能会被阻塞,等待另一侧的q.get,而另一侧正在等待p.join,而p.join又被q.put阻塞。此外,q.qsize和q.empty大多只存在于与非多进程Queue库的接口兼容性。在某些情况下(管理线程的竞争条件),它不可靠。mp.manager队列没有这个问题,因为它们是非 mp 队列的代理(尽管这意味着它们也更慢)。 - Aaron