在Python中,假设有以下pandas的DataFrame数据:
date ID_bulb switch using_time error
2022-02-05 14:30:21+00:00 5 OFF NaT INIT
2022-02-27 15:30:21+00:00 5 ON NaT ERROR2
2022-02-27 17:05:21+00:00 5 OFF 0 days 01:35:00 OK
2022-04-07 15:30:21+00:00 5 ON NaT OK
2022-04-07 15:30:21+00:00 5 OFF 0 days 00:00:00 OK
2022-04-07 17:05:21+00:00 5 OFF NaT ERROR2
2022-04-06 15:30:21+00:00 4 ON NaT INIT
2022-04-06 15:35:21+00:00 4 OFF NaT ERROR1
2022-04-06 16:10:21+00:00 4 ON NaT ERROR2
2022-04-07 15:30:21+00:00 4 OFF 0 days 23:20:00 OK
2022-04-07 17:05:21+00:00 4 ON NaT ERROR2
2022-01-01 19:40:21+00:00 3 ON NaT INIT
2022-02-03 22:40:21+00:00 3 ON NaT ERROR2
2022-02-03 23:20:21+00:00 3 OFF 0 days 00:40:00 OK
2022-02-04 00:20:21+00:00 3 ON NaT OK
2022-02-04 14:30:21+00:00 3 ON NaT ERROR2
2022-02-04 15:30:21+00:00 3 ON NaT ERROR2
2022-02-04 15:35:21+00:00 3 OFF 0 days 00:05:00 OK
2022-02-04 15:40:21+00:00 3 OFF NaT ERROR2
2022-02-04 19:40:21+00:00 3 ON NaT OK
2022-02-06 15:35:21+00:00 3 OFF 1 days 19:55:00 OK
2022-02-28 18:40:21+00:00 3 ON NaT ERROR1
2022-10-12 18:40:21+00:00 3 OFF 226 days 00:00:00 OK
2022-02-04 09:10:21+00:00 2 ON NaT OK
2022-02-04 14:10:21+00:00 2 ON NaT ERROR2
需要解决的问题: 我想添加一个名为cost_days的新列。该列只包括变量using_time与NaT不同的行。在start_time到end_time定义的夜间周期中,至少连续n小时亮着的灯泡次数信息。
基于@keramat的想法提出的解决方案.
def rounder(x):
# Fixed parameters, to be at least 5 hours in the interval from 22:00 to 07:00
n = 5
start_date = "22:00"
end_date = "07:00"
# assert (n+1) < time_slot
time_1 = datetime.strptime(start_date,"%H:%M")
time_2 = datetime.strptime(end_date,"%H:%M")
time_slot = (time_2 - time_1).seconds // 3600
v = pd.date_range(list(x)[-2], list(x)[-1], freq='1h')
temp = pd.Series(v, index = v).between_time(start_date, end_date)
temp = len(temp)/time_slot
return np.floor(temp) if np.mod(temp, 1.0) < (n+1)/time_slot else np.ceil(temp)/time_slot
g = (df['using_time'].notna()).sort_index(ascending=False).cumsum()
g = (g-max(g)).abs()
temp = df.groupby(g)['date'].apply(lambda x: rounder(x))
#Up to this point, it runs perfectly.
df.loc[df[df['using_time'].notna()].index, 'cost_days']=temp.values
# ValueError: shape mismatch: value array of shape (8,) could not be broadcast to indexing result of shape (7,)
df['cost_days'] = df['cost_days'].fillna(0)
print(df)
我需要修复错误以获得想要的结果。
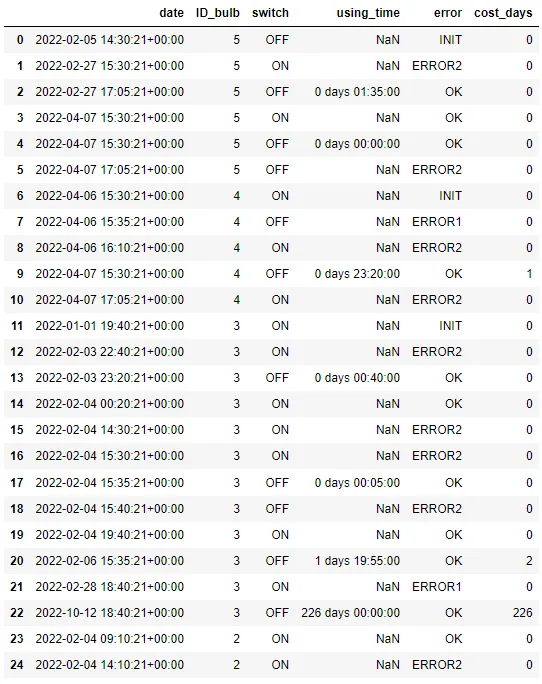
生成的数据框应如下所示:
date ID_bulb switch using_time error cost_days
2022-02-05 14:30:21+00:00 5 OFF NaT INIT 0
2022-02-27 15:30:21+00:00 5 ON NaT ERROR2 0
2022-02-27 17:05:21+00:00 5 OFF 0 days 01:35:00 OK 0
2022-04-07 15:30:21+00:00 5 ON NaT OK 0
2022-04-07 15:30:21+00:00 5 OFF 0 days 00:00:00 OK 0
2022-04-07 17:05:21+00:00 5 OFF NaT ERROR2 0
2022-04-06 15:30:21+00:00 4 ON NaT INIT 0
2022-04-06 15:35:21+00:00 4 OFF NaT ERROR1 0
2022-04-06 16:10:21+00:00 4 ON NaT ERROR2 0
2022-04-07 15:30:21+00:00 4 OFF 0 days 23:20:00 OK 1
2022-04-07 17:05:21+00:00 4 ON NaT ERROR2 0
2022-01-01 19:40:21+00:00 3 ON NaT INIT 0
2022-02-03 22:40:21+00:00 3 ON NaT ERROR2 0
2022-02-03 23:20:21+00:00 3 OFF 0 days 00:40:00 OK 0
2022-02-04 00:20:21+00:00 3 ON NaT OK 0
2022-02-04 14:30:21+00:00 3 ON NaT ERROR2 0
2022-02-04 15:30:21+00:00 3 ON NaT ERROR2 0
2022-02-04 15:35:21+00:00 3 OFF 0 days 00:05:00 OK 0
2022-02-04 15:40:21+00:00 3 OFF NaT ERROR2 0
2022-02-04 19:40:21+00:00 3 ON NaT OK 0
2022-02-06 15:35:21+00:00 3 OFF 1 days 19:55:00 OK 2
2022-02-28 18:40:21+00:00 3 ON NaT ERROR1 0
2022-10-12 18:40:21+00:00 3 OFF 226 days 00:00:00 OK 226
2022-02-04 09:10:21+00:00 2 ON NaT OK 0
2022-02-04 14:10:21+00:00 2 ON NaT ERROR2 0
编辑: 我认为问题在于输入数据集必须以非空的using_time值结束,以上代码才能正常工作。如何通过修复这个问题来获得我想要的性能?
ID_bulb也不应该有影响吗?例如,如果您有一个序列:[(1, 'ON'), (2, 'ON'), (1, 'OFF')],我想'OFF'应该与(1, 'ON')行匹配,对吗? - Pierre D'ERROR1'和'ERROR2'是什么意思?例如,在2022-02-04 15:35:21,used_time为05:00,这是与上一行的时间差,尽管该行具有'ERROR2'条件。在稍微上面有一个('ON', 'OK')行,时间是2022-02-04 00:20:21;难道它不应该是时间差的起点吗?只是检查所有逻辑。 - Pierre DID_bulb很重要,但默认情况下它已经排序。error属性对此函数的操作不重要。 - Carola