我正在尝试为K均值聚类创建轮廓图,但是条形图几乎不可见。如何使此图表易于阅读?
示例代码:
require(cluster)
X <- EuStockMarkets
kmm <- kmeans(X, 8)
D <- daisy(X)
plot(silhouette(kmm$cluster, D), col=1:8)
示例输出:
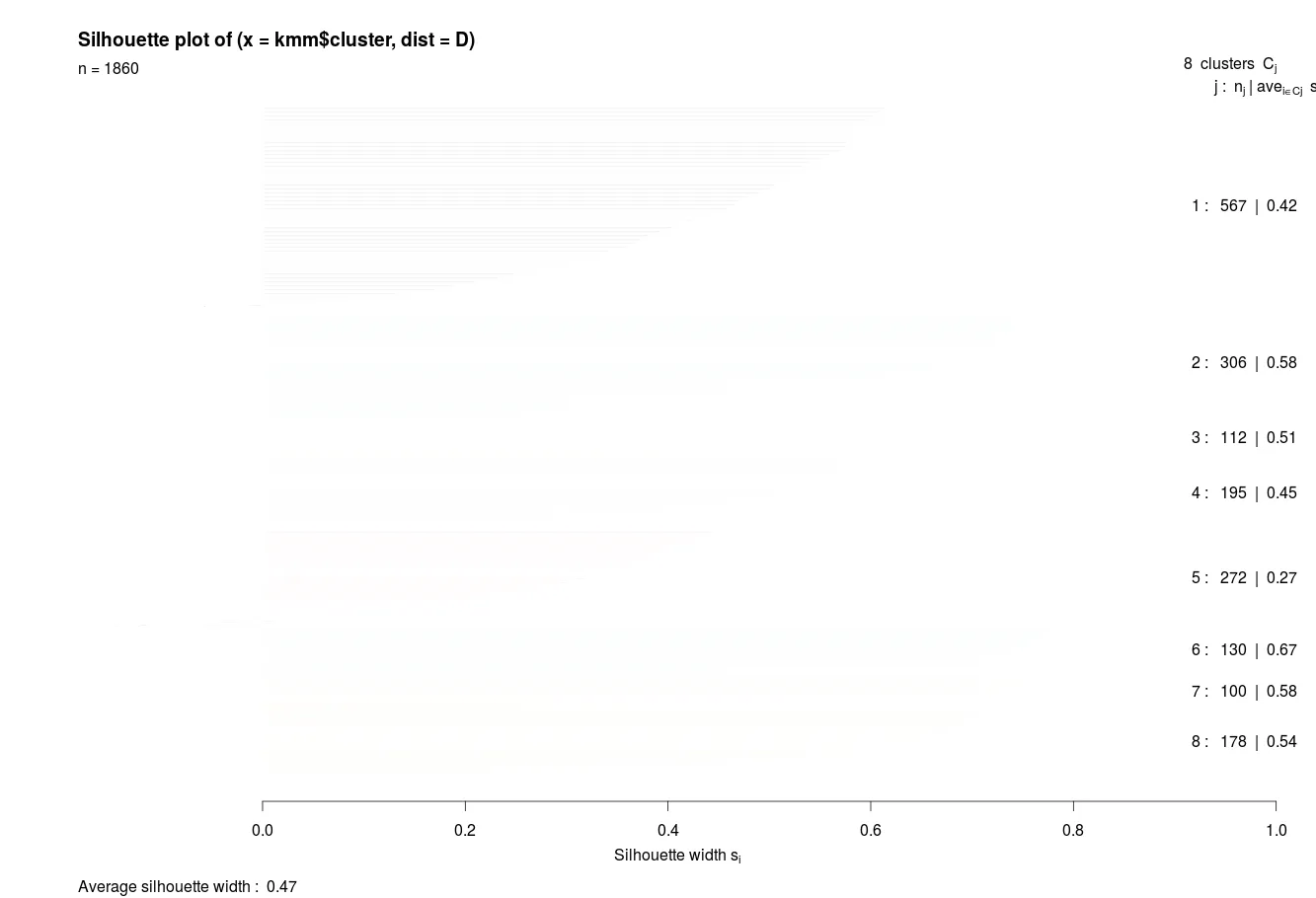
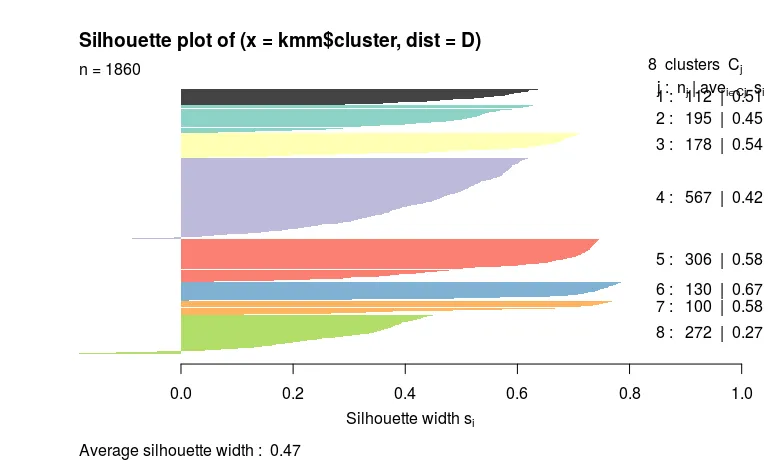
要解决这个问题,将边框设置为NA:
plot(silhouette(kmm$cluster, D), col=1:8, border=NA)
我对R还很陌生,所以可能走错了方向。你能具体说明一下列的颜色吗?就像这样:
require(cluster)
X <- EuStockMarkets
kmm <- kmeans(X, 8)
D <- daisy(X)
plot(silhouette(kmm$cluster, D), col = c("blue","red","purple","green","black","pink","peach","orange")
colors()函数可以在R中显示颜色选项。