大家好,我需要帮助获取一个base64编码的列,但是我得到的是一个sha256哈希列,应该得到44个字符,但是当我在Python中尝试时
[base64.b64encode(x.encode('utf-8')).decode() for x in xxx['yyy']]
它返回了88个字符,有人能帮忙吗?基本上我想要在Python中实现下面图片中显示的步骤,谢谢!
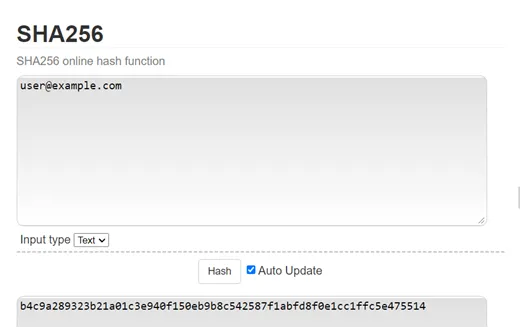
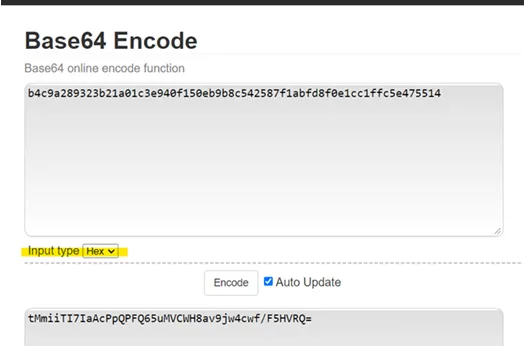

from hashlib import sha256
s = 'user@example.com'
h = sha256()
h.update(s.encode('utf-8')) # specifying encoding, optional as this is the default
hex_string = h.digest().hex()
print(hex_string)
from base64 import b64encode
digest_again = bytes.fromhex(hex_string)
b64bytes = b64encode(digest_again)
# no real need to specify 'ascii', the relevant code points overlap with UTF-8:
result = b64bytes.decode('ascii')
print(result)
组合在一起:
from hashlib import sha256
from base64 import b64encode
s = 'user@example.com'
h = sha256()
h.update(s.encode())
print(h.digest().hex())
b64bytes = b64encode(h.digest())
print(b64bytes.decode())
输出:
b4c9a289323b21a01c3e940f150eb9b8c542587f1abfd8f0e1cc1ffc5e475514
tMmiiTI7IaAcPpQPFQ65uMVCWH8av9jw4cwf/F5HVRQ=
base64.b64encode('user@example.com'.encode('utf-8')).decode() # superfluous utf-8
这段代码:
该代码没有应用SHA256哈希,也没有创建十六进制表示,如果你正在期望这些操作,最终结果会与你的期望不同。最终结果是原始文本的UTF-8编码的base64表示的文本形式,而不是其SHA256哈希值的摘要。
或者我可能误解了你的意思,你已经有了十六进制编码,但你将其作为字符串输入:
x = 'b4c9a289323b21a01c3e940f150eb9b8c542587f1abfd8f0e1cc1ffc5e475514'
base64.b64encode(x.encode()).decode()
确实会导致一个88个字符的base64编码,因为你没有对字节进行编码,而是对十六进制表示进行了编码。应该改为:
x = 'b4c9a289323b21a01c3e940f150eb9b8c542587f1abfd8f0e1cc1ffc5e475514'
base64.b64encode(bytes.fromhex(x)).decode()
也许这就是您在寻找的答案。
这个回答在密码学堆栈交换上讨论了为什么你会得到64个字符。基本上,由于历史原因,哈希通常是十六进制编码的,即使这样会导致64个字符,而Base64编码的哈希只有44个字符。但是如果您需要Base64编码,则有一种方法可以实现。以下内容将为您提供Base64编码的哈希值。
from base64 import b64encode
from hashlib import sha256
email = 'user@example.com'
email_as_bytes = email.encode('utf-8')
hash_as_bytes = b64encode(sha256(email_as_bytes).digest())
hash = hash_as_bytes.decode('utf-8')
由于b64encode和sha256都是基于字节的操作,我们可以将它们链接在一起,而且结果代码并不太糟糕。
xxx['yyy']中有多少个字符。我不知道我应该在哪里看到44或88个字符。 - hostingutilities.comb64encode('a\tb\tc\n'.encode())这样的情况下可能看起来并不是真实的 - 很容易忘记\n只有一个字符长度,即使您的操作系统通常将其编码为两个字节,而\t则始终只有一个字符。\t\n的len()是2,但经常被误认为是3或4。 - Grismar