我一直在寻找关于使用C#编写CUDA(NVIDIA GPU语言)的资料。我看过一些库,但似乎它们会增加一些开销(因为涉及到p/invokes等等)。
- 如何在我的C#应用程序中使用CUDA?还是说最好编写C++,然后将其编译为dll文件?
- 使用包装器的开销是否会抵消使用CUDA所获得的任何优势?
- 有没有使用C#的CUDA的好例子?
有一个非常完整的cuda 4.2包装器,叫做ManagedCuda。 你只需将C++ cuda项目添加到解决方案中,该项目包含您的c#项目,然后您只需添加
call "%VS100COMNTOOLS%vsvars32.bat"
for /f %%a IN ('dir /b "$(ProjectDir)Kernels\*.cu"') do nvcc -ptx -arch sm_21 -m 64 -o "$(ProjectDir)bin\Debug\%%~na_64.ptx" "$(ProjectDir)Kernels\%%~na.cu"
for /f %%a IN ('dir /b "$(ProjectDir)Kernels\*.cu"') do nvcc -ptx -arch sm_21 -m 32 -o "$(ProjectDir)bin\Debug\%%~na.ptx" "$(ProjectDir)Kernels\%%~na.cu"
为在 c# 项目属性中添加后期构建事件,需编译 *.ptx 文件并将其复制到 c# 项目输出目录。
然后,只需创建新的上下文,从文件加载模块,加载函数并使用设备即可。
//NewContext creation
CudaContext cntxt = new CudaContext();
//Module loading from precompiled .ptx in a project output folder
CUmodule cumodule = cntxt.LoadModule("kernel.ptx");
//_Z9addKernelPf - function name, can be found in *.ptx file
CudaKernel addWithCuda = new CudaKernel("_Z9addKernelPf", cumodule, cntxt);
//Create device array for data
CudaDeviceVariable<cData2> vec1_device = new CudaDeviceVariable<cData2>(num);
//Create arrays with data
cData2[] vec1 = new cData2[num];
//Copy data to device
vec1_device.CopyToDevice(vec1);
//Set grid and block dimensions
addWithCuda.GridDimensions = new dim3(8, 1, 1);
addWithCuda.BlockDimensions = new dim3(512, 1, 1);
//Run the kernel
addWithCuda.Run(
vec1_device.DevicePointer,
vec2_device.DevicePointer,
vec3_device.DevicePointer);
//Copy data from device
vec1_device.CopyToHost(vec1);
这在Nvidia的列表中曾经被评论过:
http://forums.nvidia.com/index.php?showtopic=97729
可以很容易地使用P/Invoke在程序集中使用它:
[DllImport("nvcuda")]
public static extern CUResult cuMemAlloc(ref CUdeviceptr dptr, uint bytesize);
Altimesh Hybridizer是一款高级生产力工具,它可以从.NET程序集(MSIL)或Java归档文件(Java字节码)生成矢量化的C++源代码(AVX)和CUDA C源代码。
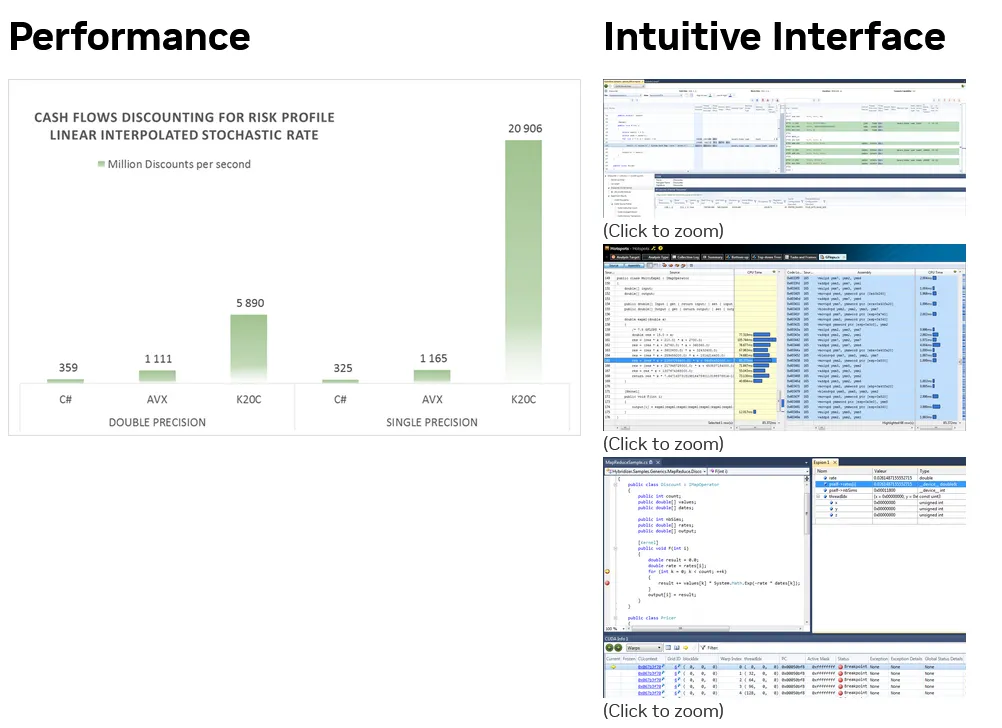
在托管开发环境中,开发人员可以使用虚函数和泛型,同时有效地利用GPU的计算能力,达到处理器和内存峰值性能的80%。从单个版本的源代码中,开发人员可以在喜欢的开发环境中调试和执行CPU和CUDA GPU,并进入原始源代码(.NET或Java)。应用程序可以使用最先进的解决方案(如VTUNE和Nsight)进行分析,引用原始源代码中的位置。
主要特点
Hybridizer有两个版本:
Hybridizer软件套件:支持CUDA、AVX、AVX2、AVX512目标,并输出源代码。该源代码可以进行审核,在一些企业如投资银行中是强制性的。Hybridizer软件套件按客户许可证授权(根据要求)。
Hybridizer Essentials:仅支持CUDA目标,并仅输出二进制文件。Hybridizer Essentials是一个免费的Visual Studio扩展程序,没有硬件限制。您可以在GitHub上找到一组基本的代码示例和教育材料。这些示例还可以作为重现我们性能结果的方法。