编辑:虽然我仍然对执行过程中遇到的问题感兴趣,但似乎严格性确实与此有关,因为
解决问题只需递归遍历树即可:
显然,这具有指数时间复杂度。因此,我尝试使用记忆化技术来记录结果:
它基本上是每次以两行列表的形式遍历列表,然后从下到上递归地创建节点。
这种方法有什么问题吗?我认为程序在到达叶子节点之前仍会生成完整的树解析thunk,因此在备忘之前避免了所有备忘的好处,但我不确定是否是这种情况。如果是这样,有没有办法修复它?
-O修复了执行并且程序可以非常快地处理树。
我已经使用简单列表和动态规划解决了它。
现在我想使用树数据结构来解决它(嗯,其中一个节点可以有两个父节点,所以它不是真正的树)。我想使用一个简单的树,但会注意在适当时共享节点:
data Tree a = Leaf a | Node a (Tree a) (Tree a) deriving (Show, Eq)
解决问题只需递归遍历树即可:
calculate :: (Ord a, Num a) => Tree a => a
calculate (Node v l r) = v + (max (calculate l) (calculate r))
calculate (Leaf v) = v
显然,这具有指数时间复杂度。因此,我尝试使用记忆化技术来记录结果:
calculate :: (Ord a, Num a) => Tree a => a
calculate = memo go
where go (Node v l r) = v + (max (calculate l) (calculate r))
go (Leaf v) = v
这里的memo来自Stable Memo。 Stable Memo 应该是基于它是否已经看到过完全相同的参数(即在内存中相同)进行记忆。
所以我使用ghc-vis来查看我的树是否正确共享节点,以避免在另一个分支中重新计算已经计算过的内容。
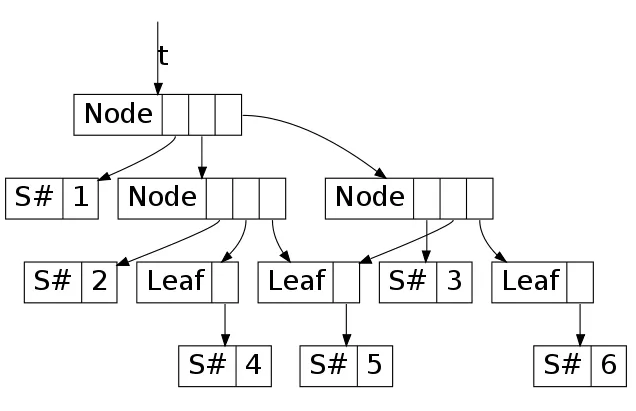
对于由函数 lists2tree [[1], [2, 3], [4, 5, 6]] 产生的样本树,它返回以下正确的共享结果:
(来源:crydee.eu)
{kind=link}
在这里,我们可以看到节点5被共享。
但是在实际的欧拉问题中,我的树似乎没有被正确地进行记忆化。代码可以在 GitHub 上找到,但我猜除了上面的 calculate 方法之外,唯一其他重要的方法就是创建树的方法。如下:
lists2tree :: [[a]] -> Tree a
lists2tree = head . l2t
l2t :: [[a]] -> [Tree a]
l2t (xs:ys:zss) = l2n xs ts t
where (t:ts) = l2t (ys:zss)
l2t (x:[]) = l2l x
l2t [] = undefined
l2n :: [a] -> [Tree a] -> Tree a -> [Tree a]
l2n (x:xs) (y:ys) p = Node x p y:l2n xs ys y
l2n [] [] _ = []
l2n _ _ _ = undefined
l2l :: [a] -> [Tree a]
l2l = map (\l -> Leaf l)
它基本上是每次以两行列表的形式遍历列表,然后从下到上递归地创建节点。
这种方法有什么问题吗?我认为程序在到达叶子节点之前仍会生成完整的树解析thunk,因此在备忘之前避免了所有备忘的好处,但我不确定是否是这种情况。如果是这样,有没有办法修复它?