这个问题是关于按未汇总表格的顺序排列条形图的。我有一个略微不同的情况。这是我的原始数据的一部分:
experiment,pvs_id,src,hrc,mqs,mcs,dmqs,imcs
dna-wm,0,7,9,4.454545454545454,1.4545454545454546,1.4545454545454541,4.3939393939393945
dna-wm,1,7,4,2.909090909090909,1.8181818181818181,0.09090909090909083,3.9090909090909087
dna-wm,2,7,1,4.818181818181818,1.4545454545454546,1.8181818181818183,4.3939393939393945
dna-wm,3,7,8,3.4545454545454546,1.5454545454545454,0.4545454545454546,4.272727272727273
dna-wm,4,7,10,3.8181818181818183,1.9090909090909092,0.8181818181818183,3.7878787878787876
dna-wm,5,7,7,3.909090909090909,1.9090909090909092,0.9090909090909092,3.7878787878787876
dna-wm,6,7,0,4.909090909090909,1.3636363636363635,1.9090909090909092,4.515151515151516
dna-wm,7,7,3,3.909090909090909,1.7272727272727273,0.9090909090909092,4.030303030303029
dna-wm,8,7,11,3.6363636363636362,1.5454545454545454,0.6363636363636362,4.272727272727273
我只需要从中提取几个变量,即mqs和imcs,按照它们的pvs_id进行分组,因此我创建了一个新表:
m = melt(t, id.var="pvs_id", measure.var=c("mqs","imcs"))
我可以把这个数据用条形图展示出来,这样人们可以看到 MQS 和 IMCS 之间的关联。
ggplot(m, aes(x=pvs_id, y=value))
+ geom_bar(aes(fill=variable), position="dodge", stat="identity")
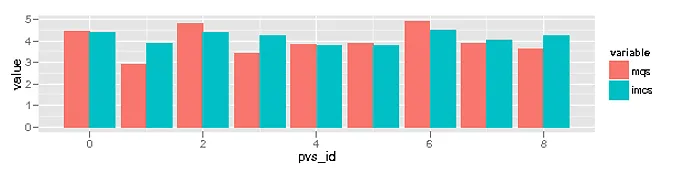
然而,我希望所得到的图形中MQS值从左到右依次递减,条形图按照这个顺序排列。当然,也需要对IMCS值进行排序。
我该如何完成这个任务呢?一般来说,在任何分子数据框中——这似乎对于在ggplot2中绘制图形很有用,今天是我第一次遇到它——如何为一个变量指定顺序?
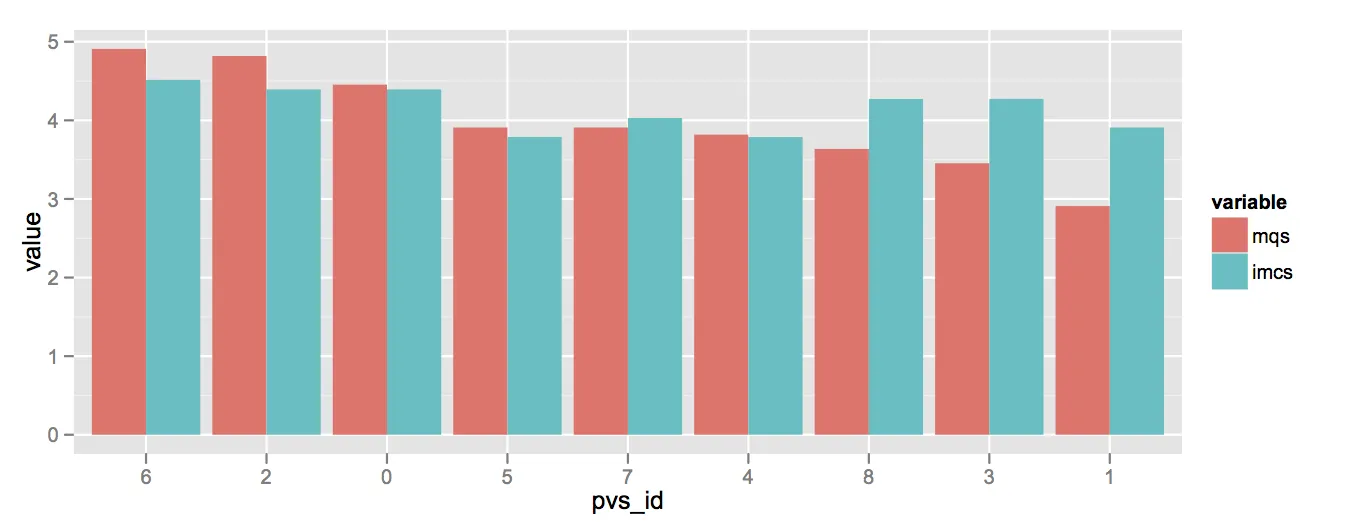
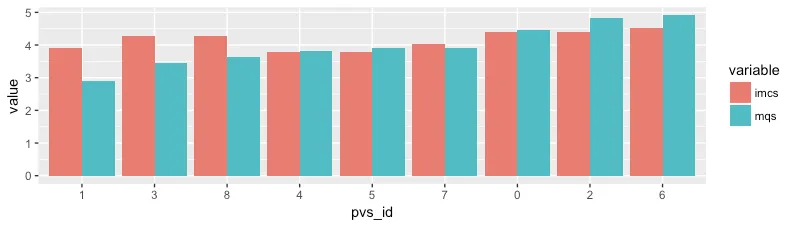
t <- 1:5; t(matrix(1:9, nrow = 3))。但如果你这样说t <- function(x) 1:x,那就会出现问题。 - Roman Luštrikdat[order(-dat$mqs), 2]返回按照mqs递减顺序排列的pvs_id值,对吗?那个具体是如何工作的呢?您能否再解释一下,以便未来的访问者可以更容易地适应这个方法? - slhck