CSV文件格式是一种方便和简单的文件格式。
它不适用于分析/快速搜索,这从未是目标。它适用于在不需要处理所有条目或条目数量不是非常庞大的不同应用程序和任务之间进行交换。
如果您想加快速度,应该读取CSV文件一次并将其转换为数据库,例如sqlite,然后在数据库中执行所有搜索。如果密码数字是唯一的,则甚至可以只使用简单的dbm文件或Python shelve。
通过为搜索字段添加索引,可以优化数据库性能。
这完全取决于CSV文件更改的频率以及执行搜索的频率,但通常这种方法应该产生更好的结果。
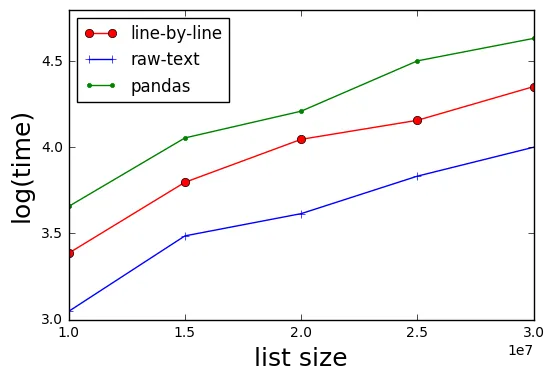
我从来没有真正使用过pandas,但也许它在搜索/过滤方面更具性能,尽管它永远无法击败在真正的数据库中进行搜索。
如果您想走sqlite或dbm的路线,我可以帮助提供一些代码。
附加说明(在使用csv阅读器读取之前在排序的csv文件中使用bisect搜索进行搜索):
如果您的csv文件中的第一个字段是序列号,则有另一种方法。(或者如果您愿意转换csv文件,使其可以使用gnu sort进行排序)
只需对文件进行排序(在Linux系统上使用gnu sort很容易实现。它可以对大型文件进行排序,而不会“耗尽”内存),排序时间不应该比您目前的搜索时间高太多。
然后,在文件中使用bisect / seek搜索找到具有正确序列号的第一行。 然后使用您现有的带有小修改的功能。
这将在几毫秒内为您提供结果。 我用一个随机创建的包含3000万条记录和约1.5G大小的csv文件进行了测试。
如果在Linux系统上运行,甚至可以更改代码,每当下载的csv文件发生更改时,就创建一个已排序的副本。(在我的机器上,排序大约需要1到2分钟。)因此,每周进行2到3次搜索后,这将是值得努力的。
import csv
import datetime
import os
def get_line_at_pos(fin, pos):
""" fetches first complete line at offset pos
always skips header line
"""
fin.seek(pos)
skip = fin.readline()
npos = fin.tell()
assert pos + len(skip) == npos
line = fin.readline()
return npos, line
def bisect_seek(fname, field_func, field_val):
""" returns a file postion, which guarantees, that you will
encounter all lines, that migth encounter field_val
if the file is ordered by field_val.
field_func is the function to extract field_val from a line
The search is a bisect search, with a complexity of log(n)
"""
size = os.path.getsize(fname)
minpos, maxpos, cur = 0, size, int(size / 2)
with open(fname) as fin:
small_pos = 0
state = "?"
prev_pos = -1
while True:
pos_str = "%s %10d %10d %10d" % (state, minpos, cur, maxpos)
realpos, line = get_line_at_pos(fin, cur)
val = field_func(line)
pos_str += "# got @%d: %r %r" % (realpos, val, line)
if val >= field_val:
state = ">"
maxpos = cur
cur = int((minpos + cur) / 2)
else:
state = "<"
minpos = cur
cur = int((cur + maxpos) / 2)
if prev_pos == cur:
break
prev_pos = cur
return realpos
def getser(line):
return line.split(",")[0]
def check_passport(filename, series: str, number: str) -> dict:
"""
Find passport number and series
:param filename:csv filename path
:param series: passport series
:param number: passport number
:return:
"""
print(f'series={series}, number={number}')
found = False
start = datetime.datetime.now()
pos = bisect_seek(filename, getser, series)
with open(filename, 'r', encoding='utf_8_sig') as csvfile:
csvfile.seek(pos)
reader = csv.reader(csvfile, delimiter=',')
try:
for row in reader:
if row[0] == series and row[1] == number:
found = True
break
elif row[0] > series:
break
except Exception as e:
print(e)
print(datetime.datetime.now() - start)
if found:
print("good row", row)
return {'result': True, 'message': f'Passport found'}
else:
print("bad row", row)
return {'result': False, 'message': f'Passport not found in Database'}
补充 2019-11-30:
这里有一个脚本,可以将你的大文件分成更小的块,并对每个块进行排序。(我不想实现完整的归并排序,因为在这种情况下,在每个块中搜索已经足够高效了。如果有兴趣了解更多,请尝试实现归并排序或发布一个关于如何使用Python在Windows下对大文件进行排序的问题。)
split_n_sort_csv.py:
import itertools
import sys
import time
def main():
args = sys.argv[1:]
t = t0 = time.time()
with open(args[0]) as fin:
headline = next(fin)
for idx in itertools.count():
print(idx, "r")
tprev = t
lines = list(itertools.islice(fin, 10000000))
t = time.time()
t_read = t - tprev
tprev = t
print("s")
lines.sort()
t = time.time()
t_sort = t - tprev
tprev = t
print("w")
with open("bla_%03d.csv" % idx, "w") as fout:
fout.write(headline)
for line in lines:
fout.write(line)
t = time.time()
t_write = t - tprev
tprev = t
print("%4.1f %4.1f %4.1f" % (t_read, t_sort, t_write))
if not lines:
break
t = time.time()
print("Total of %5.1fs" % (t-t0))
if __name__ == "__main__":
main()
这是一份修改后的版本,它可以搜索所有块文件。
import csv
import datetime
import itertools
import os
ENCODING='utf_8_sig'
def get_line_at_pos(fin, pos, enc_encoding="utf_8"):
""" fetches first complete line at offset pos
always skips header line
"""
while True:
fin.seek(pos)
try:
skip = fin.readline()
break
except UnicodeDecodeError:
pos += 1
npos = fin.tell()
assert pos + len(skip.encode(enc_encoding)) == npos
line = fin.readline()
return npos, line
def bisect_seek(fname, field_func, field_val, encoding=ENCODING):
size = os.path.getsize(fname)
vmin, vmax, cur = 0, size, int(size / 2)
if encoding.endswith("_sig"):
enc_encoding = encoding[:-4]
else:
enc_encoding = encoding
with open(fname, encoding=encoding) as fin:
small_pos = 0
state = "?"
prev_pos = -1
while True:
pos_str = "%s %10d %10d %10d" % (state, vmin, cur, vmax)
realpos, line = get_line_at_pos(fin, cur, enc_encoding=enc_encoding)
val = field_func(line)
pos_str += "# got @%d: %r %r" % (realpos, val, line)
if val >= field_val:
state = ">"
vmax = cur
cur = int((vmin + cur) / 2)
else:
state = "<"
vmin = cur
cur = int((cur + vmax) / 2)
if prev_pos == cur:
break
prev_pos = cur
return realpos
def getser(line):
return line.split(",")[0]
def check_passport(filename, series: str, number: str,
encoding=ENCODING) -> dict:
"""
Find passport number and series
:param filename:csv filename path
:param series: passport series
:param number: passport number
:return:
"""
print(f'series={series}, number={number}')
found = False
start = datetime.datetime.now()
for ctr in itertools.count():
fname = filename % ctr
if not os.path.exists(fname):
break
print(fname)
pos = bisect_seek(fname, getser, series)
with open(fname, 'r', encoding=encoding) as csvfile:
csvfile.seek(pos)
reader = csv.reader(csvfile, delimiter=',')
try:
for row in reader:
if row[0] == series and row[1] == number:
found = True
break
elif row[0] > series:
break
except Exception as e:
print(e)
if found:
break
print(datetime.datetime.now() - start)
if found:
print("good row in %s: %d", (fname, row))
return {'result': True, 'message': f'Passport found'}
else:
print("bad row", row)
return {'result': False, 'message': f'Passport not found in Database'}
测试时,请使用以下方式调用:
check_passport("bla_%03d.csv", series, number)
df['columnname'].str.contains(series)而不是遍历每一行。 - Zephyrus3.csv中存储所有系列为3xxx的数字,6.csv中存储所有系列为6xxx的数字。这样一来,你只需要读取和检查较少的数据行。或者你可以按照系列对数据进行排序,并创建第二个包含信息的文件,指示3xxx、6xxx等系列的起始位置(就像数据库中的索引),然后仅从文件中读取部分数据。或者你应该将其写入数据库,并使用数据库进行处理。 - furas