我有一组轴对齐的矩形。当两个矩形重叠(部分或完全)时,它们将合并为它们的公共边界框。此过程递归进行。
检测所有重叠并使用并查集形成组,在最后合并将不起作用,因为两个矩形的合并覆盖了更大的区域,并且可能会创建新的重叠。(在下面的图中,两个重叠的矩形合并后,出现了新的重叠。)
检测所有重叠并使用并查集形成组,在最后合并将不起作用,因为两个矩形的合并覆盖了更大的区域,并且可能会创建新的重叠。(在下面的图中,两个重叠的矩形合并后,出现了新的重叠。)
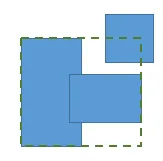
由于我这里的矩形数量较少(比如说N<100),所以可以使用暴力解法(尝试所有的矩形对,如果发现重叠,则合并并重新开始)。但是我想要降低复杂度,最坏情况下可能为O(N³)。
有什么建议可以改进吗?
可以合并不是必须合并。) - greybeard