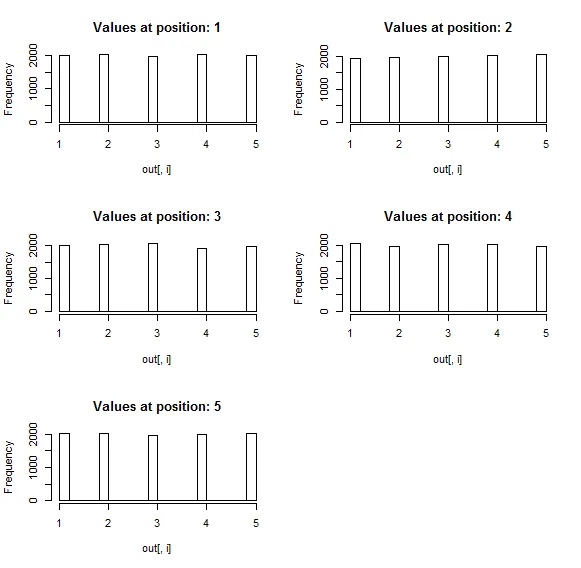
我正在编写一项心理实验,需要为每个参与者随机排列刺激顺序。我有一个函数可以随机排列我的刺激,然后我的程序从一个.txt文件中读取它们的顺序。默认情况下,在我的“shuffle”函数中使用的伪随机算法是否足够混淆事物,以便在实验过程中(4500次试验)不会产生任何系统偏差,无论是在任何刺激位置还是刺激位置模式上?
stimulus <- c("a", "b", "c", "d", "e")
shuffle <- function (x) { as.data.frame(sample((t(x)))) }
shuffle (stimulus)