免责声明:我只有使用X86机器码的经验。其他指令集可能具有不同的寻址能力,因此我的建议可能不适用于某些部分。非常抱歉,我现在没有时间研究指令集。
首先,大多数编译器不会生成文本形式的汇编代码,因为将代码串行化成汇编代码再由汇编器解析会很低效,你可能已经意识到了。在编译和汇编两个阶段中,可以选择拆分这两个阶段,但这并非必要。
在编译阶段,我考虑的两种策略是:
我猜测像GCC这样的优化编译器使用的是(a)方法,而像TCC这样的高速编译器使用的是(b)方法。
让我们再考虑下if的例子,并通过检查现有编译器为简单的if/else分支生成的代码来进行分析:
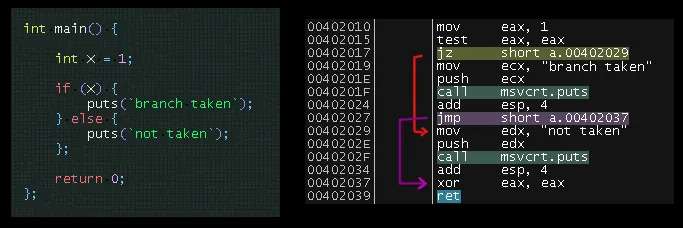
请注意汇编代码中重叠的跳转 - 一个跳过了“taken”块,另一个跳过了“not-taken”块。
这些是相对跳转,因此要将它们汇编起来,我们需要知道跳转指令和目标之间有多少字节的指令。
以下示例使用策略(a)的编译函数可能如下所示:
Instruction[] compile_if(IfNode n) {
Instruction[] code;
code ~= compile_condition(n.condition);
Instruction skip_taken = new JumpInstruction(`jz`);
code ~= skip_taken;
code ~= compile_block(n.taken_block);
Instruction skip_nottaken = new JumpInstruction(`jmp`);
code ~= skip_nottaken;
Instruction[] nottaken_code = compile_block(n.nottaken_block);
skip_taken.destination = nottaken_code[0];
code ~= nottaken_code;
Instruction end = new NopInstruction();
skip_nottaken.destination = end;
code ~= end;
return code;
};
这应该相当易懂。
请注意,指令使用符号(例如
skip_taken.destination = nottaken_code[0])而不是像串行化机器码那样使用字节偏移。我们将这些偏移计算留给汇编器处理。
还要注意,我们只在
JumpInstruction可用时才设置它们的目标。
结尾处的
NopInstruction只是为了给
skip_nottaken跳转提供一个参照物。
那么,如何将这些跳转组装成真正的机器码/字节码呢?以下是一种可能性(非常基本的例子):
byte[2] assemble_jz(Instruction[] code, int idx) {
JumpInstruction jump = code[idx];
++idx;
byte jump_offset = 0;
while (code[idx] != jump.destination) {
jump_offset += size_of_instruction(code[idx]);
++idx;
};
byte[2] machinecode = [
0x74,
jump_offset
];
return machinecode;
};
由于汇编器可以访问所有指令对象,因此它可以通过向前扫描直到找到目标指令来计算相对跳转的实际偏移量。
我希望这个简短的介绍能帮助你开始设计自己的编译器后端。显然,我并不建议您完全像我的示例那样编写编译器,但它应该会给您一些如何处理编译和组装非线性指令块的通用问题的思路。
您可能还想查看一些现有的汇编器 API,例如 https://github.com/asmjit/asmjit。
祝你好运。