它们是编译过程的不同阶段生成的吗?还是只是指称同一件事情的不同名称?
解析树和抽象语法树(AST)有什么区别?
127
- Thomson
1
解析树是由你的语法及其产物组成的结果(你可以为同一语言编写无限多个语法),抽象语法树将解析树尽可能接近语言进行简化。同一语言的几个语法将生成不同的解析树,但应导致相同的抽象语法树。(也可以将来自同一语法的不同脚本(不同的解析树)简化为相同的抽象语法树) - Guillaume86
8个回答
119
这是基于Terrence Parr的表达式求值器语法的。
这个例子的语法:
这个例子的语法:
grammar Expr002;
options
{
output=AST;
ASTLabelType=CommonTree; // type of $stat.tree ref etc...
}
prog : ( stat )+ ;
stat : expr NEWLINE -> expr
| ID '=' expr NEWLINE -> ^('=' ID expr)
| NEWLINE ->
;
expr : multExpr (( '+'^ | '-'^ ) multExpr)*
;
multExpr
: atom ('*'^ atom)*
;
atom : INT
| ID
| '('! expr ')'!
;
ID : ('a'..'z' | 'A'..'Z' )+ ;
INT : '0'..'9'+ ;
NEWLINE : '\r'? '\n' ;
WS : ( ' ' | '\t' )+ { skip(); } ;
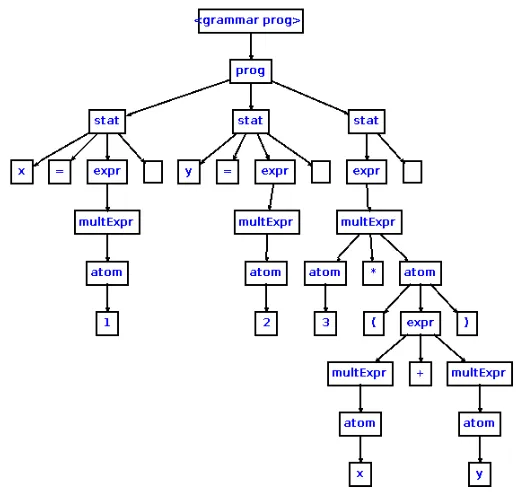
输入
x=1
y=2
3*(x+y)
解析树
解析树是输入的具体表示。解析树保留了输入的所有信息。空白框表示空格,即行末。
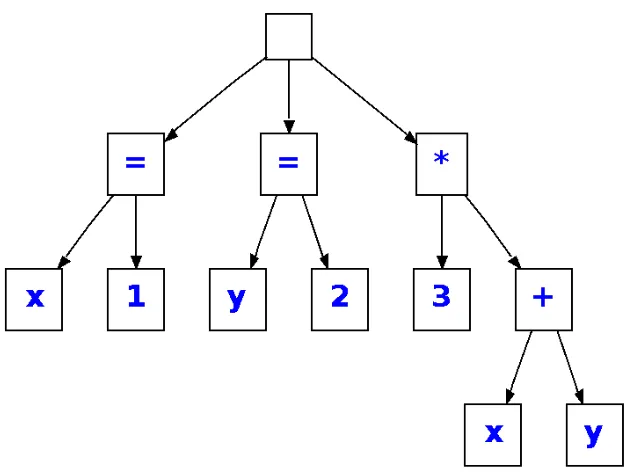
AST
抽象语法树(AST)是输入的一种抽象表示。请注意,AST中没有括号,因为关联性可以从树结构中推导出来。
如需更详细的解释,请参见编译器和编译器生成器第23页
或抽象语法树在编程语言的语法和语义中的第21页
- Guy Coder
6
10如何从解析树中推导出抽象语法树?将解析树简化为抽象语法树的方法是什么? - CMCDragonkai
6从语法树中推导出抽象语法树没有具体的算法。AST 中包含什么更多是个人喜好,但必须包含足够的信息来完成任务。我在语法规则中使用 ANTLR [! 运算符](https://theantlrguy.atlassian.net/wiki/display/ANTLR3/Tree+construction)来排除了 AST 中的括号,因为它们是不必要的,但默认情况下 ANTLR 会将它们包含在内。我认为语法树提供了一切(无论你是否需要),而 AST 提供的是最少的内容。请记住,您将经常遍历这些树,所以大小很重要。 - Guy Coder
2你是指像具体语法树 (CST) 和抽象语法树 (AST) 这样的吗? - CMCDragonkai
语义动作/规则嵌入解析器或解析器生成器的语法文件中是语义分析和创建AST的常见方式,而解析树很少被构建或由用户代码使用,除了用于解析器正确性验证。 - user246672
44
这里介绍编译器构建中的解析树(具体语法树,CST)和抽象语法树(AST)。它们是类似的数据结构,但构造方式不同并用于不同的任务。
它们是树状数据结构,显示了输入终端符号串(源代码标记)如何由所涉及的语言的语法生成。解析树的根是语法的最一般符号 - 开始符号(例如statement),内部节点表示开始符号扩展到的非终止符号(可以包括开始符号本身),例如expression、statement、term、function call。叶子是语法的终结符,实际上出现在语言/输入字符串中的符号,例如for、9、if等。
在解析期间,编译器还执行各种检查以确保语法正确 - 语法错误报告可以嵌入解析器代码中。
可以通过语法定向定义或翻译方案使用它们进行语法定向翻译,例如将中缀表达式转换为后缀表达式。
这里是一个解析树的图形表示,用于表达式
以下是相同表达式的抽象语法树:
解析树
解析树通常在词法分析之后生成(将源代码转换为一系列可以视为有意义单元而不仅仅是字符序列的标记)。它们是树状数据结构,显示了输入终端符号串(源代码标记)如何由所涉及的语言的语法生成。解析树的根是语法的最一般符号 - 开始符号(例如statement),内部节点表示开始符号扩展到的非终止符号(可以包括开始符号本身),例如expression、statement、term、function call。叶子是语法的终结符,实际上出现在语言/输入字符串中的符号,例如for、9、if等。
在解析期间,编译器还执行各种检查以确保语法正确 - 语法错误报告可以嵌入解析器代码中。
可以通过语法定向定义或翻译方案使用它们进行语法定向翻译,例如将中缀表达式转换为后缀表达式。
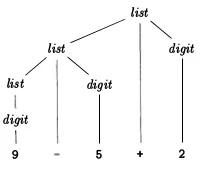
这里是一个解析树的图形表示,用于表达式
9-5+2(注意终端在树中的位置和来自表达式字符串的实际符号):
抽象语法树
抽象语法树是一种以计算机程序的抽象语法结构表示代码的树状表现形式。与解析树不同,它们通常在解析期间生成,并且它们的结构与编程语言无关。它们可以被视为解析树的精简版,去掉了冗余信息并根据代码的实际含义进行了组织。例如,它们可能删除括号和其他运算符,将操作数提到父节点,并使用单个节点表示流程控制语句等。以下是相同表达式的抽象语法树:

抽象语法树(AST)代表了一些代码的语法结构。编程结构的树形式如表达式、流控制语句等被分为运算符(内部节点)和操作数(叶节点)。例如,表达式 i+9 的语法树将以 + 运算符作为根节点,变量 i 作为左儿子,数字 9 作为右儿子。
这里的区别在于非终结符和终结符不起作用,因为 AST 不处理语法和字符串生成,而是处理编程结构,因此它们表示这些结构之间的关系,而不是它们由语法生成的方式。
请注意,运算符本身是给定语言中的编程结构,不必是实际的计算运算符(如 +),例如:for 循环也会以这种方式处理。例如,您可以拥有类似于 for [ expr, expr, expr, stmnt ] 的语法树(内联表示),其中 for 是一个 运算符,方括号内的元素是其子元素(表示 C 的 for 语法),还由运算符等组成。
AST 通常由编译器在语法分析(解析)阶段生成,并在后续用于语义分析、中间表示、代码生成等。
以下是抽象语法树的图形表示:
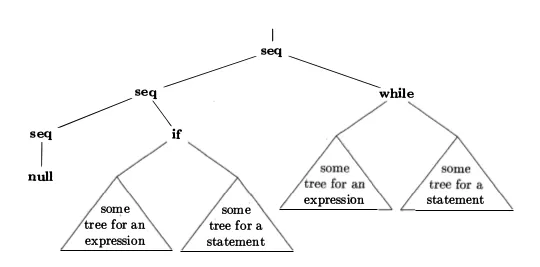
- corazza
3
11我希望你的回答能被认可。它更加详细,解释得更好。 - Salil
1@Salil 谢谢! :) 我也在我的博客上写了一些关于这些事情的内容: http://flowing.systems/tag/mcd - corazza
有没有任何作者第一次定义解析树? - duichwer
20
据我所了解,AST更关注源代码组件之间的抽象关系,而解析树则更关注语言所使用的语法实现,包括细节方面。它们绝对不是相同的,因为“解析树”的另一个术语是“具体语法树”。
- Ken Wayne VanderLinde
3
1链接未指向正确的信息。 - Hrishikesh Devhare
1感谢@HrishikeshDevhare。我已经将它删除了,因为保留它没有任何意义了。 - Ken Wayne VanderLinde
可以通过Wayback Machine访问。https://web.archive.org/web/20020803201420/http://www.jguru.com/faq/view.jsp?EID=814505我阅读了一下。@KenWayneVanderLinde - Ali Mert Çakar
13
抽象语法树(AST)描述源代码的概念,它不需要包含解析某些源代码所需的所有语法元素(大括号、关键字、括号等)。
语法分析树更加贴近源代码。
在AST中,IF语句的节点可能只包含三个子节点:
- 条件
- IF条件成立时执行的代码块
- ELSE条件成立时执行的代码块
对于类C语言,语法分析树需要包含 'if' 关键字、括号和大括号等节点。
- jjwchoy
7
维基百科表示
解析树具体地反映了输入语言的语法,使其与用于计算机编程的抽象语法树不同。
Quora上的答案说
解析树是记录用于匹配某些输入文本的规则(和令牌)的记录,而语法树记录输入的结构并对生成它的语法不敏感。
结合上述两个定义,
抽象语法树在逻辑上描述解析树。它不需要包含解析某些源代码所需的所有语法结构(空格、花括号、关键字、括号等)。这就是为什么解析树也被称为具体语法树,而AST被称为语法树。因此,语法分析器的输出实际上是语法树。
- Palak Jain
5
进行pascal任务分配
Age:= 42;
语法树看起来就像源代码一样。下面我将在节点周围放置括号。 [Age][:=][42][;]
抽象树如下所示 [=][Age][42]
该赋值成为一个具有两个元素的节点,即Age和42。其想法是可以执行该赋值。
还要注意Pascal语法消失的事实。因此,可以有多种语言生成相同的AST。对于跨语言脚本引擎很有用。
- William Egge
4
在解析树中,内部节点是非终端节点,叶子节点是终端节点。
在语法树中,内部节点是运算符,叶子节点是操作数。
- Roshani Patel
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接