我之前修过离散数学(其中学习了主定理、大Omega/Theta/O等),但似乎已经忘记了O(logn)和O(2^n)之间的区别(不是在大O理论意义下的区别)。通常情况下,我知道像归并排序和快速排序这样的算法是O(nlogn),因为它们将初始输入数组重复分成子数组,直到每个子数组的大小都是1,然后在递归回到树的顶层之前进行排序。这样得到的递归树高度为logn+1。但是如果使用n/b^x = 1(如在此答案中所述),计算递归树的高度,则似乎总是得到树的高度为log(n)。
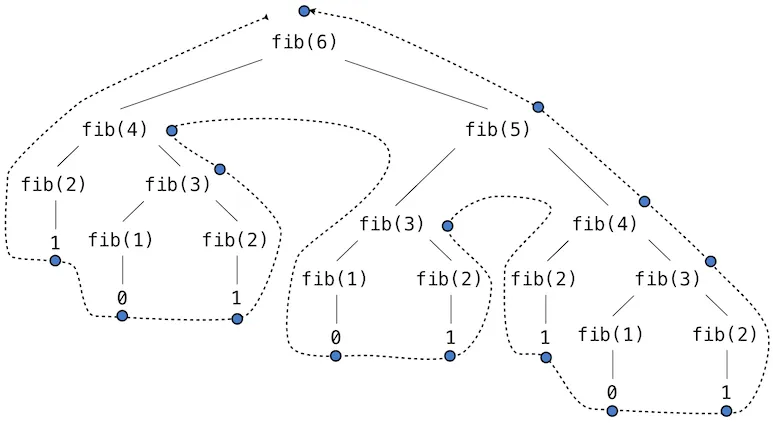
如果使用递归来解决斐波那契数列,我认为您也会得到一棵大小为logn的树,但由于某种原因,该算法的时间复杂度却是O(2^n)。我认为可能的差异是因为您必须记住每个子问题的所有斐波那契数字才能获得实际的斐波那契数字,这意味着必须重新调用每个节点的值,但是似乎在归并排序中,也必须使用(或至少排序)每个节点的值。然而,这与二分搜索不同,因为基于树的每个层次的比较仅访问某些节点,所以我认为这就是混淆的原因。
因此,具体来说,是什么导致斐波那契数列具有与归并/快速排序等算法不同的时间复杂度?