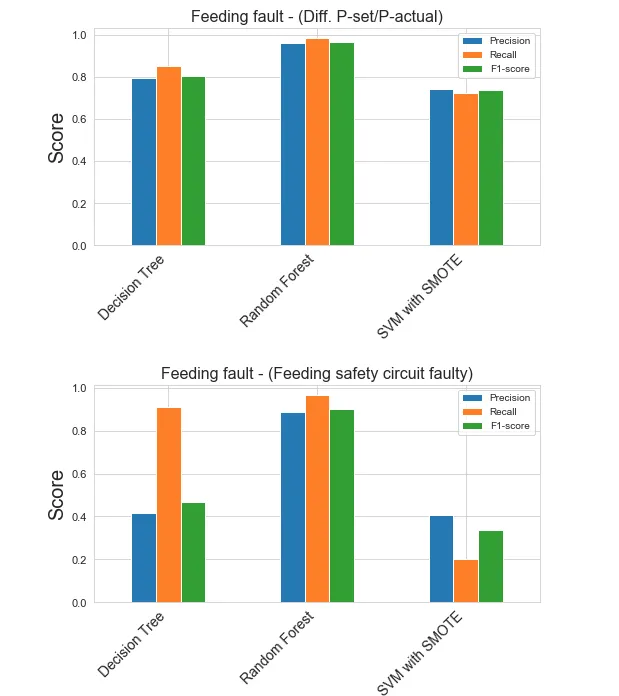
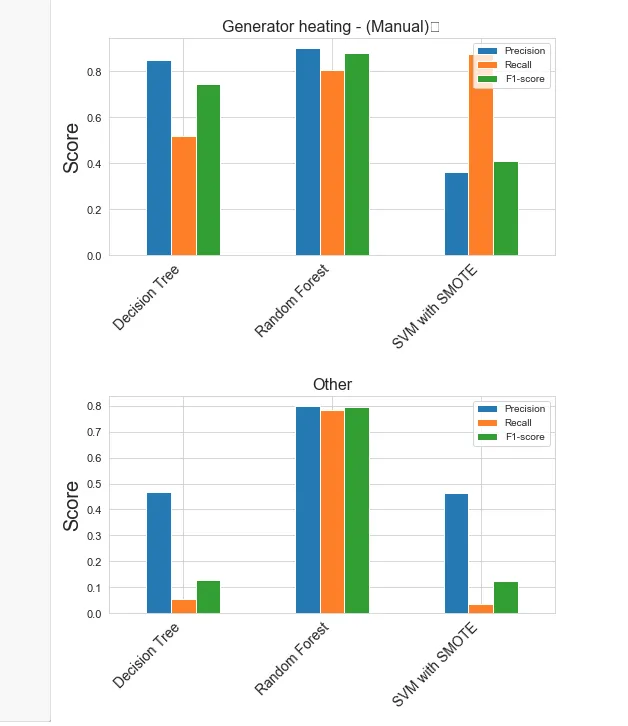
在评估SVM、RF和DT(max_depth = 3)的性能时,我发现RF模型的结果非常优秀。所建模型的数据是真实世界的数据。由于数据集不平衡,它们都使用分层交叉验证进行评估。
对于之前看到的4个不同类别,我得到了这些精确度、召回率和F1得分。
原始数据集包含以下4个类别的values_counts:
1. 饲料故障-(Diff. P-set/P-actual):4,098条数据样本 2. 饲料故障-(饲料安全电路故障):383条数据样本 3. 发电机加热:228,668条数据样本 4. 其他:51,966,851个样本
RF为何比SVM和DT表现更好呢?
提前感谢!
对于之前看到的4个不同类别,我得到了这些精确度、召回率和F1得分。
原始数据集包含以下4个类别的values_counts:
1. 饲料故障-(Diff. P-set/P-actual):4,098条数据样本 2. 饲料故障-(饲料安全电路故障):383条数据样本 3. 发电机加热:228,668条数据样本 4. 其他:51,966,851个样本
RF为何比SVM和DT表现更好呢?
提前感谢!