使用前一个问题中的数据:
d = {'Col1': {(Timestamp('2015-05-14 00:00:00'), '10'): 81.370003,
(Timestamp('2015-05-14 00:00:00'), '11'): 80.41999799999999,
(Timestamp('2015-05-14 00:00:00'), 'C3'): 80.879997,
(Timestamp('2015-05-19 00:00:00'), '3'): 80.629997,
(Timestamp('2015-05-19 00:00:00'), 'S9'): 80.550003,
(Timestamp('2015-05-21 00:00:00'), '19'): 80.480003,
(Timestamp('2015-05-22 00:00:00'), 'C3'): 80.540001},
'Col2': {(Timestamp('2015-05-14 00:00:00'), '10'): 6.11282,
(Timestamp('2015-05-14 00:00:00'), '11'): 6.0338,
(Timestamp('2015-05-14 00:00:00'), 'C3'): 6.00746,
(Timestamp('2015-05-19 00:00:00'), '3'): 6.10465,
(Timestamp('2015-05-19 00:00:00'), 'S9'): 6.1437,
(Timestamp('2015-05-21 00:00:00'), '19'): 6.16096,
(Timestamp('2015-05-22 00:00:00'), 'C3'): 6.1391599999999995},
'Col3': {(Timestamp('2015-05-14 00:00:00'), '10'): 39.753,
(Timestamp('2015-05-14 00:00:00'), '11'): 39.289,
(Timestamp('2015-05-14 00:00:00'), 'C3'): 41.248999999999995,
(Timestamp('2015-05-19 00:00:00'), '3'): 41.047,
(Timestamp('2015-05-19 00:00:00'), 'S9'): 41.636,
(Timestamp('2015-05-21 00:00:00'), '19'): 42.137,
(Timestamp('2015-05-22 00:00:00'), 'C3'): 42.178999999999995},
'Col4': {(Timestamp('2015-05-14 00:00:00'), '10'): 44.950001,
(Timestamp('2015-05-14 00:00:00'), '11'): 44.75,
(Timestamp('2015-05-14 00:00:00'), 'C3'): 44.360001000000004,
(Timestamp('2015-05-19 00:00:00'), '3'): 40.98,
(Timestamp('2015-05-19 00:00:00'), 'S9'): 42.790001000000004,
(Timestamp('2015-05-21 00:00:00'), '19'): 43.68,
(Timestamp('2015-05-22 00:00:00'), 'C3'): 43.490002000000004}}
df = pd.Dataframe(d)
接下来,您可以使用部分字符串索引来选择一段日期范围:
df.loc['2015-05-14':'2015-05-19']
输出:
Col1 Col2 Col3 Col4
2015-05-14 10 81.370003 6.11282 39.753 44.950001
11 80.419998 6.03380 39.289 44.750000
C3 80.879997 6.00746 41.249 44.360001
2015-05-19 3 80.629997 6.10465 41.047 40.980000
S9 80.550003 6.14370 41.636 42.790001
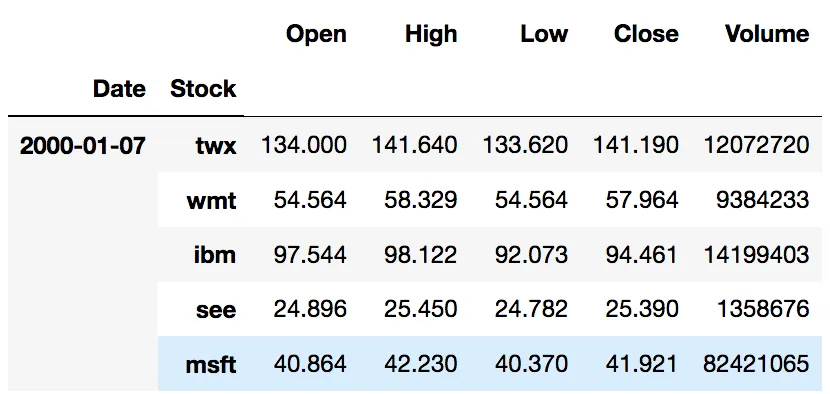
df1.sort_index().loc(axis=0)[:,'2015-05-14':'2015-05-19'],其中df1 = df.swaplevel(0,1)。 - Scott Boston