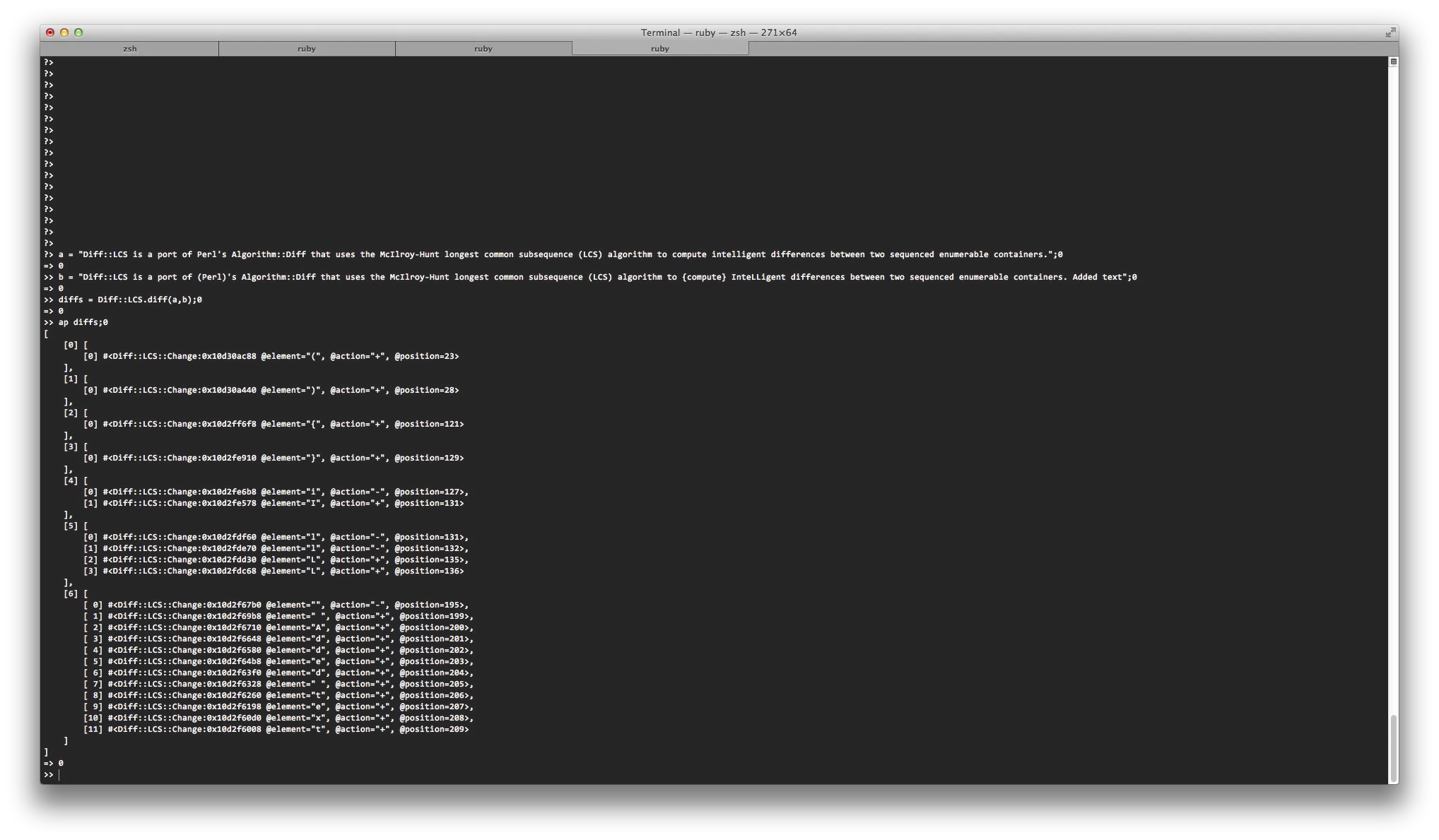
所以,我希望能够按单词基础找到两个字符串之间的差异(如果按字符比较快,则可能更快,但是如果按字符比较快,则我想以这种方式执行)。
以下是我想要实现的示例: 源文本:
Hello there!
抱歉,我只能以英文回答。
Helay scere?
差异:
Hel[lo](ay) [th](sc)ere[!](?)
- 方括号内的文本是被删除的内容,括号内的文本是添加的内容。
有一种非常hackish的方法可以使用命令行工具(例如opendiff),但它需要在每个字符之间插入换行符,因为opendiff是基于行的。
我正在使用ruby,并没有找到任何工具来做到这一点... 但语言并不是非常重要,因为算法可以很容易地移植。
谢谢。