安装
以下硬件可以运行我将要描述的内容:
- 磁盘:6块2TB的HDD组成RAID5(带1个冗余驱动器)
- CPU:Intel Xeon E5-2640 @ 2.4 GHz,6核
- 内存:64 GB
- SQL Server版本:SQL Server 2016 Developer
SQL Server Management Studio(SSMS)和sql server实例都在此服务器上运行。因此,所有查询都在本地执行。此外,在执行任何查询之前,我始终运行以下命令以确保没有数据访问被缓存在内存中:
DBCC DROPCLEANBUFFERS
问题
我们有一个大约有11,600,000行的SQL Server表。在整体方案中,这不是特别大的表,但它会随着时间的推移而不断增长。
该表具有以下结构:
CREATE TABLE [Trajectory](
[Id] [int] IDENTITY(1,1) NOT NULL,
[FlightDate] [date] NOT NULL,
[EntryTime] [datetime2] NOT NULL,
[ExitTime] [datetime2] NOT NULL,
[Geography] [geography] NOT NULL,
[GreatArcDistance] [real] NULL,
CONSTRAINT [PK_Trajectory] PRIMARY KEY CLUSTERED ([Id])
)
为了简化,一些列被排除在外,但它们的数量和大小非常小。
虽然行数不是很多,但由于[Geography]列,表占用了相当大的磁盘空间。该列的内容是具有大约3000个点(包括Z和M值)的LINESTRINGS。
现在,我们只需考虑在表的Id列上有一个聚集索引,该索引也表示DDL中描述的主键约束。
我们遇到的问题是,当我们查询日期范围和特定地理交叉点时,完成该查询需要相当长的时间。
我们要查询的查询如下:
DEFINE @p1 = [...]
SELECT [Id], [Geography]--, (+ some other columns)
WHERE [FlightDate] BETWEEN '2018-09-04' AND '2018-09-12' AND [Geography].STIntersects(@p1) = 1
这是一个相当简单的查询,具有我上面提到的两个过滤器。为了使查询速度快,我们尝试了几种不同类型的索引:
1. CREATE NONCLUSTERED INDEX [IX_Trajectory_FlightDate] ON [Trajectory] ([FlightDate] ASC)
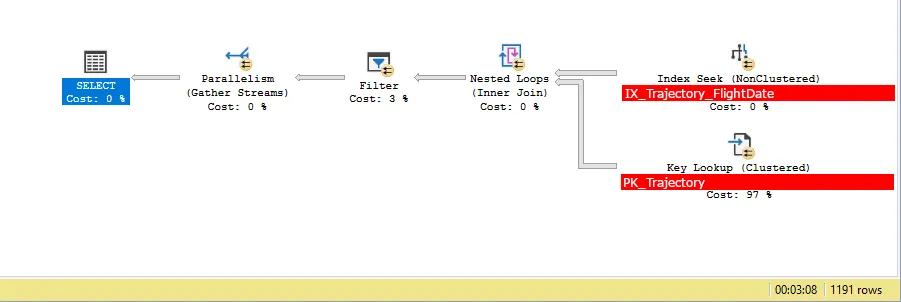
当我们查询表时,在添加此类索引后,期望的查询计划如下所示:
- 在索引上执行INDEX SEEK操作(此操作将11,600,000行的数据筛选为大约50,000行)
- 查找主表以获取[Geography]列及任何其他选择的列
- 对返回的每一行执行地理筛选
[Geography].STIntersects(@p1) = 1
--- 更新1开始 ---
其他查询计划信息(针对主要步骤,注意:与上面显示的查询不是同一次执行,因此时间会有所变化。这个查询花费了2分39秒):
SELECT.QueryTimeStatsCpuTime=12241毫秒ElapsedTime=157591毫秒
Key Lookup (97%)Actual I/O StatisticsActual Logical Reads=48165Actual Physical Reads=81
Actual Time StatisticsActual Elapsed CPU Time=144毫秒Actual Elapsed Time=266毫秒
Index Seek (0%)Actual I/O StatisticsActual Logical Reads=85Actual Physical Reads=0Actual Read Aheads=73Actual Scans=21
Filter (3%)Actual Time StatisticsActual Elapsed CPU Time=12156毫秒Actual Elapsed Time=157583毫秒
- 它表明,耗时/资源的3%步骤需要157583ms,而耗时/资源的97%步骤只需要266ms。我觉得这很奇怪。
- 如果我用一个不使用索引的不同过滤器(使用
EntryTime列代替),它大致返回相同数量的行,那么查询时间将缩短到大约20秒,尽管我仍然选择相同数量的行。我想唯一的解释是,在可以丢弃行之前,查询实际上并不需要读取昂贵的[Geography]列。
--- UPDATE 1 END ---
2. CREATE NONCLUSTERED INDEX [IX_Trajectory_FlightDate_Includes_Geography] ON [Trajectory] ([FlightDate] ASC) INCLUDE ([Geography])
这个索引唯一不同的地方就是它将大型的[Geography]列与索引一起存储。但是对于查询计划的期望基本相同:
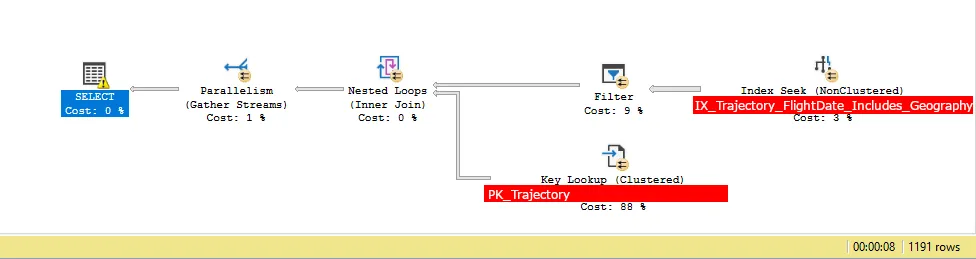
当我们查询该表时,添加了如下索引后,期望的查询计划应该是这样的:- 在索引上执行INDEX SEEK操作(此操作将把11600000行数据过滤到大约50000行)
- 对返回的每一行执行地理筛选器
[Geography].STIntersects(@p1) = 1 - 查找主表以获得额外选择的列
现在,维护这样的索引并不是我们想要做的理想情况,因为考虑到表中的[Geography]列有多大以及它将来会增长多少,它使用了相当多的空间。像这样重建索引需要几个小时。
--- UPDATE 2 START ---
其他查询计划信息:
SELECT.QueryTimeStatsCpuTime=11648msElapsedTime=7533ms
Key Lookup (88%)Actual I/O StatisticsActual Logical Reads=1191Actual Physical Reads=0
Actual Time StatisticsActual Elapsed CPU Time=0msActual Elapsed Time=0ms
Index Seek (3%)Actual I/O StatisticsActual Logical Reads=7119Actual Physical Reads=4Actual Read Aheads=6678Actual Scans=21
Actual Time StatisticsActual Elapsed CPU Time=104msActual Elapsed Time=168ms
Filter (9%)Actual Time StatisticsActual Elapsed CPU Time=11535msActual Elapsed Time=6888ms
关于统计数据的补充说明:
- 当深入研究大多数这些数字时,它们在可用线程之间分配得非常好。
- 我的猜测是,这些统计数据的主要收获是,在“键查找”期间,此查询花费的时间恰好为零,而其他查询则必须大量进行IO工作。我不确定为什么它在这方面要好得多,因为它仍然必须找到另外选择的列(我选择的那个不是
[Geography]列)。但由于过滤器已经应用于查找之前,因此显然必须做得少得多。但即便如此,零IO也让我感到困惑。 - 物理读取非常少。所有所需数据(包括[Geography]列)仅通过4个物理读取从索引搜索中读取。
--- 更新2结束 ---
3. 修改表格使其按([FlightDate] ASC,[Id] ASC)聚集
现在,考虑到我们已经考虑将表进行分区,我们还考虑更改聚集索引,使其包括[FlightDate]。请查看以下SQL DDL:
ALTER TABLE [Trajectory] DROP CONSTRAINT [PK_Trajectory]
ALTER TABLE [Trajectory] ADD CONSTRAINT [PK_Trajectory] PRIMARY KEY CLUSTERED ([FlightDate] ASC, [Id] ASC)
CREATE UNIQUE INDEX [AK_Trajectory] ON [Trajectory] ([Id] ASC)
这将更改表,使其现在基于[FlightDate]聚集,然后是[Id],确保唯一性。此外,我们在[Id]上添加了一个备用键约束,因此理论上仍然可以用于引用表格。
这三个SQL语句需要几个小时才能完成,但这样做的额外好处是,它非常容易在未来对[FlightDate]进行分区,从而允许在针对表格进行的所有查询中进行分区消除。
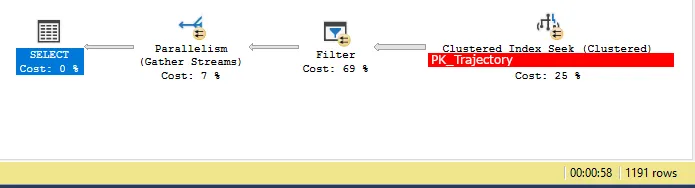
我们现在执行相同的查询到表时的预期是查询计划如下:
1.在索引上执行聚集索引查找(此操作将将11600000行过滤为大约50000)
2.在返回的每一行上执行地理筛选器[Geography].STIntersects(@p1)=1
这是比前面的示例中描述的查询计划更简单的查询计划,实际上它确实使用了此计划,如下所示:
我有一个额外的评论可能会很有趣: 即使我不删除之前创建的索引([IX_Trajectory_FlightDate_Includes_Geography]),在像这样改变表结构后,查询也会很慢。但是,如果我提示查询编译器应该使用前一节中使用的替代键创建的索引[AK_Trajectory]和[IX_Trajectory_FlightDate_Includes_Geography],使用WITH (INDEX([AK_Trajectory], [IX_Trajectory_FlightDate_Includes_Geography])),那么查询的性能将与(2)中大致相同。
因此,SQL Server实际上积极决定使用较慢的查询计划,显然认为它更快。老实说,我不怪它。我会做同样的事情,因为那个查询计划简单得多。发生了什么事?
现在,您可能会有疑问,我们是否考虑将
[Geography]列添加SPATIAL INDEX。这是一个考虑因素。这种索引的问题(以及为什么它实际上无法使用)有两个方面:
[FlightDate]索引能够过滤掉比这种索引更多的[Trajectory]行。问题的关键在于,随着表的增长,这种 SPATIAL INDEX "SEEK" 的结果会线性增长,而[FlightDate]上的INDEX SEEK则不会。- 维护这样的 SPATIAL INDEX 是昂贵的,并且插入操作会随着索引变得越来越大而变得越来越慢。
--- UPDATE 3 START ---
其他查询计划信息(主要步骤,注意:与上面显示的查询的执行不同,因此时间上有所变化。此查询花费了0:49):
SELECT.QueryTimeStatsCpuTime=11818msElapsedTime=48253ms
Parallelism (7%)Actual Time StatisticsActual Elapsed CPU Time=7msActual Elapsed Time=47638ms
Clustered Index Seek (25%)Actual I/O StatisticsActual Logical Reads=7403Actual Physical Reads=4Actual Read Aheads=6939Actual Scans=21
Actual Time StatisticsActual Elapsed CPU Time=107msActual Elapsed Time=57ms
Filter (69%)Actual Time StatisticsActual Elapsed CPU Time=11727msActual Elapsed Time=48250ms
- 聚集索引中的逻辑读取在所有线程之间分散。
- 预读取不会在线程之间分散(但其他索引也不会如此)。
- 不确定这些内容如何解释为什么这比索引#2慢。
Lucky Brain建议可能会更慢,因为数据实际上存储在ROW_OVERFLOW_DATA页面而不是IN_ROW_PAGES中。以下是对表中数据实际存储方式的更详细查看,使用以下查询进行查询:
SELECT
OBJECT_SCHEMA_NAME(p.object_id) table_schema,
OBJECT_NAME(p.object_id) table_name,
p.index_id,
p.partition_number,
au.allocation_unit_id,
au.type_desc,
au.total_pages,
au.used_pages,
au.data_pages
FROM sys.system_internals_allocation_units au
JOIN sys.partitions p
ON au.container_id = p.partition_id
WHERE OBJECT_NAME(p.object_id) = 'Trajectory'
ORDER BY table_schema, table_name, p.index_id, p.partition_number, au.type;
这提供了有关如何存储主表(聚集索引)和每个其他索引的数据的信息。其结果为:
聚集索引IN_ROW_DATA: total_pages=705137, used_pages=705137, data_pages=697811LOB_DATA: total_pages=10302796, used_pages=10248361, data_pages=0ROW_OVERFLOW_DATA: total_pages=9, used_pages=2, data_pages=0
索引 #2IN_ROW_DATA: total_pages=497639, used_pages=494629, data_pages=496531LOB_DATA: total_pages=10219824, used_pages=10217546, data_pages=0ROW_OVERFLOW_DATA: ------------------------------------------------------------
但正如上面所述,主表(聚集索引)和索引#2都使用LOB_DATA页面,因此我不完全确定为什么索引#2会快得多,除非LOB_DATA在与聚集索引相比时对于索引意味着不同的东西。
但我觉得我看到的一切都支持同样的结论:
当查询需要在包含
LOB_DATA数据的主表上进行查找时,即使它作为聚集索引的一部分执行索引搜索,该查找也总是非常缓慢。基本上我所做的每个查询(快或慢)都表明了这一点。例如,考虑索引#1:
- 使用原始查询,它将不得不进行大约50000次键查找,需要近3分钟才能完成。
- 如果我更改查询以便通过[EntryTime](示例已在
UPDATE 1中解释)对其进行过滤,以使结果集保持大致相等(约1000行左右),则查询突然需要约20秒钟。这种更改意味着它只需针对实际结果集在主表中进行到LOB_DATA页面的查找,而不是在索引#1中寻找的所有50000个条目。 (重要的是,它仍然必须对所有内容进行主表的键查找,但不需要为每个条目转到LOB_DATA。) - 但是,虽然20秒比3分钟快得多,但它仍然不及使用索引#2执行的原始查询(必须触及所有50000个[Geometry]值!)。现在我感觉唯一合理的解释是,对主表的
LOB_DATA进行查找会显着减慢查询速度。 - 我认为这可以解释索引#1和索引#2之间性能差异的相当大的差异。而索引#2和聚集索引#3之间的差异则不是那么明显。
--- 更新 4 结束 ---
--- 更新 5 开始 ---
前一个更新包括两个索引的物理页面统计信息,这里是第一个索引的相同统计信息:
索引 #1IN_ROW_DATA:total_pages=18705,used_pages=18698,data_pages=18659LOB_DATA:--------------------------------------------------ROW_OVERFLOW_DATA:--------------------------------------------------
显然,这不包括LOB_DATA或ROW_OVERFLOW_DATA。但更令人惊讶的是,IN_ROW_DATA使用的页面数量比索引 #2少得多(大约20-30个数量级)。这表明,正如Lucky Brain所建议的那样,当在索引中包括空间列时,SQL Server可能会将有关该几何/地理信息的某些信息(例如边界框)直接存储在IN_ROW_DATA中,以便快速执行几何操作。
当然,这假设表在作为聚集索引的一部分时没有针对“常规”空间列执行此操作。
--- 更新 5 结束 ---
问题
有人能回答以下两个问题吗:
- 是否可能简单的查找操作可以解释(1)和(2)中描述的索引之间性能差异?
- 为什么(3)中描述的聚集索引比(2)中的索引慢得多?
- 如果以上两个问题都无法回答,当比较1和2中描述的这两个索引时,我们应该看到如此大的性能差距吗?还是我们的设置可能出了其他问题?
DBCC DROPCLEANBUFFERS的情况下重复操作,以评估热缓存时间。存储引擎可能会在冷缓存的情况下表现不同。 - Dan Guzman