在Python中,我想知道是否有一种方法可以将一个单列数据框从这样的形式转换为:
 转换为这样的形式:
转换为这样的形式:
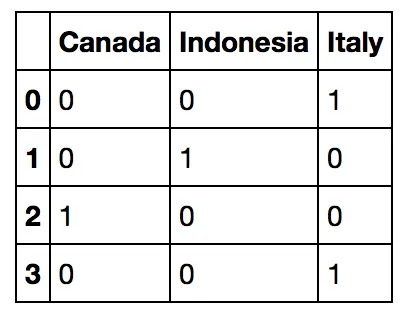
转换为这样的形式:
来源 DF:
In [204]: df
Out[204]:
Country
0 Italy
1 Indonesia
2 Canada
3 Italy
In [205]: pd.get_dummies(df.Country)
Out[205]:
Canada Indonesia Italy
0 0 0 1
1 0 1 0
2 1 0 0
3 0 0 1
In [211]: from sklearn.feature_extraction.text import CountVectorizer
In [212]: cv = CountVectorizer()
In [213]: r = pd.SparseDataFrame(cv.fit_transform(df.Country),
columns=cv.get_feature_names(),
index=df.index,
default_fill_value=0)
In [214]: r
Out[214]:
canada indonesia italy
0 0 0 1
1 0 1 0
2 1 0 0
3 0 0 1
几个附加选项
pd.Series.str.get_dummies
df.Country.str.get_dummies()
Canada Indonesia Italy
0 0 0 1
1 0 1 0
2 1 0 0
3 0 0 1
pd.DataFrame.groupby与value_counts一起使用
df.groupby(level=0).Country.value_counts().unstack(fill_value=0)
Country Canada Indonesia Italy
0 0 0 1
1 0 1 0
2 1 0 0
3 0 0 1
pd.factorize + np.bincount
f, u = pd.factorize(df.Country.values)
pd.DataFrame(
np.bincount(
f + np.arange(f.size) * u.size, minlength=u.size * f.size
).reshape(f.size, u.size),
df.index, u
)
Italy Indonesia Canada
0 1 0 0
1 0 1 0
2 0 0 1
3 1 0 0
pd.factorize + np.eye
f, u = pd.factorize(df.Country.values)
pd.DataFrame(np.eye(u.size, dtype=int)[f], df.index, u)
Italy Indonesia Canada
0 1 0 0
1 0 1 0
2 0 0 1
3 1 0 0
pd.factorize + 数组切片赋值
f, u = pd.factorize(df.Country.values)
a = np.zeros((f.size, u.size), dtype=int)
a[np.arange(f.size), f] = 1
pd.DataFrame(a, df.index, u)
Italy Indonesia Canada
0 1 0 0
1 0 1 0
2 0 0 1
3 1 0 0