另一种可能性是使用机器学习。我的背景是自然语言处理(不是计算机视觉),但我尝试使用您问题的描述创建训练和测试集,似乎可以工作(在未见过的数据上达到100%的准确度)。
训练集
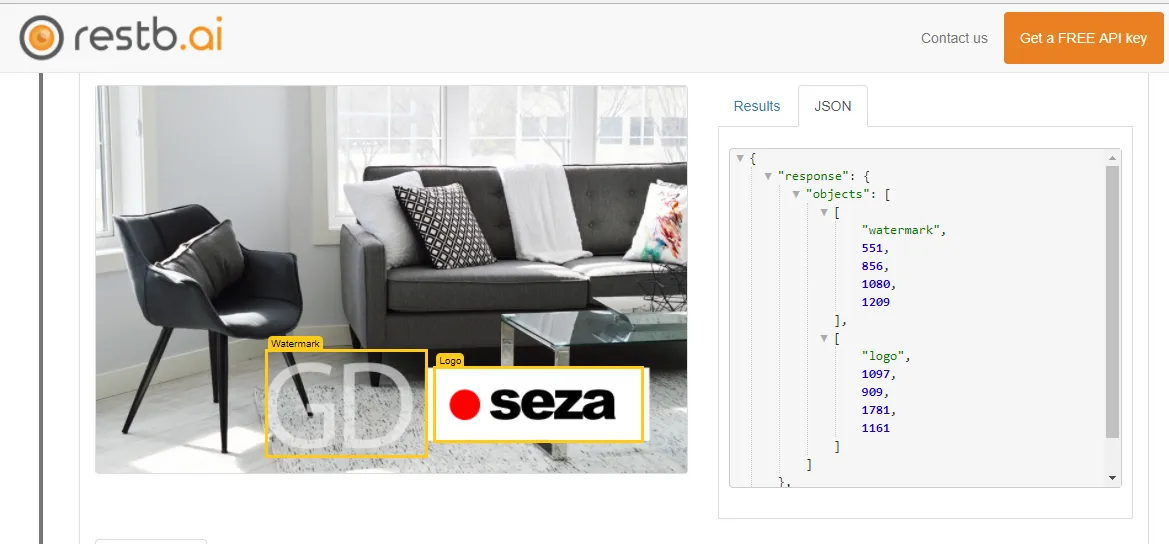
训练集由具有水印的相同图像(正面示例)和没有水印的图像(负面示例)组成。
测试集
测试集包括未在训练集中出现的图像。
示例数据
如果有兴趣,可以使用示例训练和测试图像进行尝试。
代码:
完整版本可在 gist 上找到。以下是摘录:
import glob
from classify import MultinomialNB
from PIL import Image
TRAINING_POSITIVE = 'training-positive/*.jpg'
TRAINING_NEGATIVE = 'training-negative/*.jpg'
TEST_POSITIVE = 'test-positive/*.jpg'
TEST_NEGATIVE = 'test-negative/*.jpg'
CROP_WIDTH, CROP_HEIGHT = 100, 100
RESIZED = (16, 16)
def get_image_data(infile):
image = Image.open(infile)
width, height = image.size
box = width - CROP_WIDTH, 0, width, CROP_HEIGHT
region = image.crop(box)
resized = region.resize(RESIZED)
data = resized.getdata()
data = [sum(pixel) / 3 for pixel in data]
values = []
for location, value in enumerate(data):
values.extend([location] * value)
return values
def main():
watermark = MultinomialNB()
count = 0
for infile in glob.glob(TRAINING_POSITIVE):
data = get_image_data(infile)
watermark.train((data, 'positive'))
count += 1
print 'Training', count
for infile in glob.glob(TRAINING_NEGATIVE):
data = get_image_data(infile)
watermark.train((data, 'negative'))
count += 1
print 'Training', count
correct, total = 0, 0
for infile in glob.glob(TEST_POSITIVE):
data = get_image_data(infile)
prediction = watermark.classify(data)
if prediction.label == 'positive':
correct += 1
total += 1
print 'Testing ({0} / {1})'.format(correct, total)
for infile in glob.glob(TEST_NEGATIVE):
data = get_image_data(infile)
prediction = watermark.classify(data)
if prediction.label == 'negative':
correct += 1
total += 1
print 'Testing ({0} / {1})'.format(correct, total)
print 'Got', correct, 'out of', total, 'correct'
if __name__ == '__main__':
main()
示例输出
Training 1
Training 2
Training 3
Training 4
Training 5
Training 6
Training 7
Training 8
Training 9
Training 10
Training 11
Training 12
Training 13
Training 14
Testing (1 / 1)
Testing (2 / 2)
Testing (3 / 3)
Testing (4 / 4)
Testing (5 / 5)
Testing (6 / 6)
Testing (7 / 7)
Testing (8 / 8)
Testing (9 / 9)
Testing (10 / 10)
Got 10 out of 10 correct
[Finished in 3.5s]
{kind=link}