我有一些纵向/面板数据,采用以下形式(数据输入的代码在问题下方)。 X和y的观测值按时间和国家进行索引(例如,时间1的美国,时间2的美国,时间1的加拿大)。
time x y
USA 1 5 10
USA 2 5 12
USA 3 6 13
CAN 1 2 2
CAN 2 2 3
CAN 3 4 5
我正在使用sklearn来预测y。为了得到可重复的示例,我们可以使用线性回归。
为了进行交叉验证,我不能使用test_train_split,因为这样切分可能会把time=3的数据放入X_train中,而将time=2的数据放入y_test中。这是无助于我们的,因为在time=2时,我们尝试预测y时,实际上还没有在time=3上的数据用于训练。
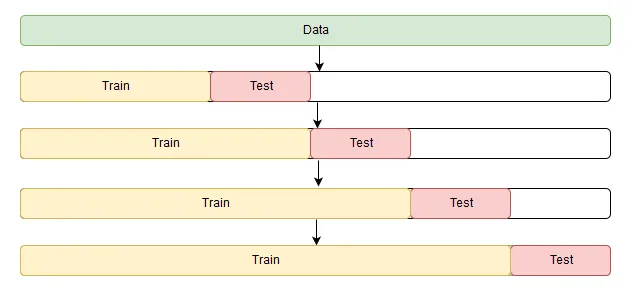
我试图使用TimeSeriesSplit来实现交叉验证,如下图所示:
y = df.y
X = df.drop(['y'], 1)
print(y)
print(X)
from sklearn.model_selection import TimeSeriesSplit
X = X.to_numpy()
from sklearn.model_selection import TimeSeriesSplit
tscv = TimeSeriesSplit(n_splits = 2, max_train_size=3)
print(tscv)
for train_index, test_index in tscv.split(X):
print("TRAIN:", train_index, "TEST:", test_index)
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
我需要的差不多就是这样,但还不完全一样:
TRAIN: [0 1] TEST: [2 3]
TRAIN: [1 2 3] TEST: [4 5]
- 我如何使用
TimeSeriesSplit索引对模型进行交叉验证?
我认为一个困难在于我的数据不是严格的时间序列:它不仅按time索引,还按country索引,因此数据具有纵向/面板的性质。
我的期望输出是:
- 一系列的测试和训练索引,允许我执行“前向逐步”交叉验证
例如:
TRAIN: [1] TEST: [2]
TRAIN: [1 2] TEST: [3]
根据上述索引值,基于
time的值,将X_train、x_test、y_test和y_train拆分成训练集和测试集,或者确保是否需要这样做。使用“前向步进”交叉验证方法对任何模型(例如线性回归)进行精度评分。
import numpy as np
import pandas as pd
data = np.array([['country','time','x','y'],
['USA',1, 5, 10],
['USA',2, 5, 12],
['USA',3,6, 13],
['CAN',1,2, 2],
['CAN',2,2, 3],
['CAN',3,4, 5]],
)
df = pd.DataFrame(data=data[1:,1:],
index=data[1:,0],
columns=data[0,1:])
df