根据scikit-learn的文档
sklearn.model_selection.cross_val_score(estimator, X, y=None, groups=None, scoring=None, cv=None, n_jobs=1, verbose=0, fit_params=None, pre_dispatch=‘2*n_jobs’)
X和y
X:类似数组的数据。可以是列表或数组等类型。
y:类似数组的数据,可选,默认值为None。在监督学习中,要尝试预测的目标变量。
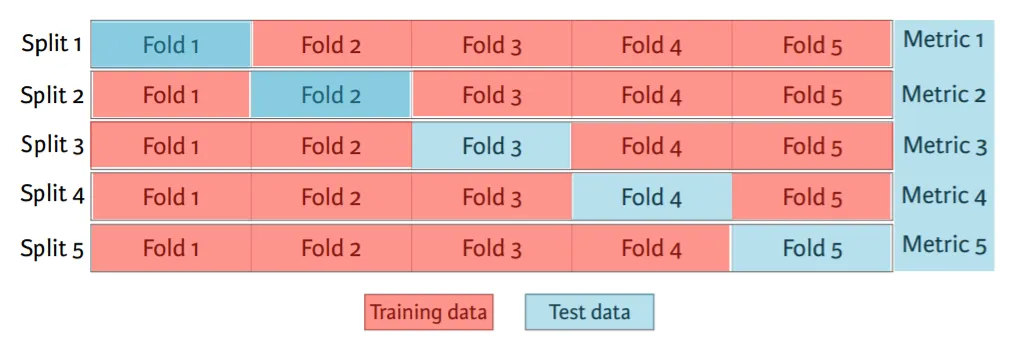
我想知道[X,y]是指X_train和y_train还是指整个数据集。在一些kaggle笔记本中,有些人使用整个数据集,而有些人则使用X_train和y_train。
据我所知,交叉验证只是评估模型,显示您是否过度拟合/欠拟合了数据(它实际上并不训练模型)。因此,在我的观点中,您拥有的数据越多,性能就越好,因此我会使用整个数据集。
你怎么看?